
概率论基础模型(用到多少,学多少 =_=)
Bayes' rule
Question One: What's the mean of Bayesian inference ?
“推理”(inference)是指“从样本数据出发,得出带有一定置信度的一般性结论的行为”。术语“贝叶斯”(Bayesian)则用来指代那些使用概率理论来表示“置信度”(即确定程度)并利用 贝叶斯公式(Bayes’ rule) 根据观察数据更新置信度的方法。
贝叶斯公式本身非常简单:它是一个用于计算在给定观测数据
这个公式可以由以下恒等式直接推出:
而这个恒等式又来自于概率的乘法法则(product rule)。
在公式 (2.51) 中,术语
术语
将先验概率
通过对每个
我们可以用一句话来总结贝叶斯公式:
这里使用符号
使用贝叶斯公式,根据观测数据对某一感兴趣的未知量的分布进行更新的过程,被称为贝叶斯推理(Bayesian inference)或后验推理(posterior inference),也可以简称为概率推理(probabilistic inference)。
Bayes 公式人话版本: “先有预期 + 接收信息 → 更新判断”
Inverse problems
概率论的核心是:在已知世界状态
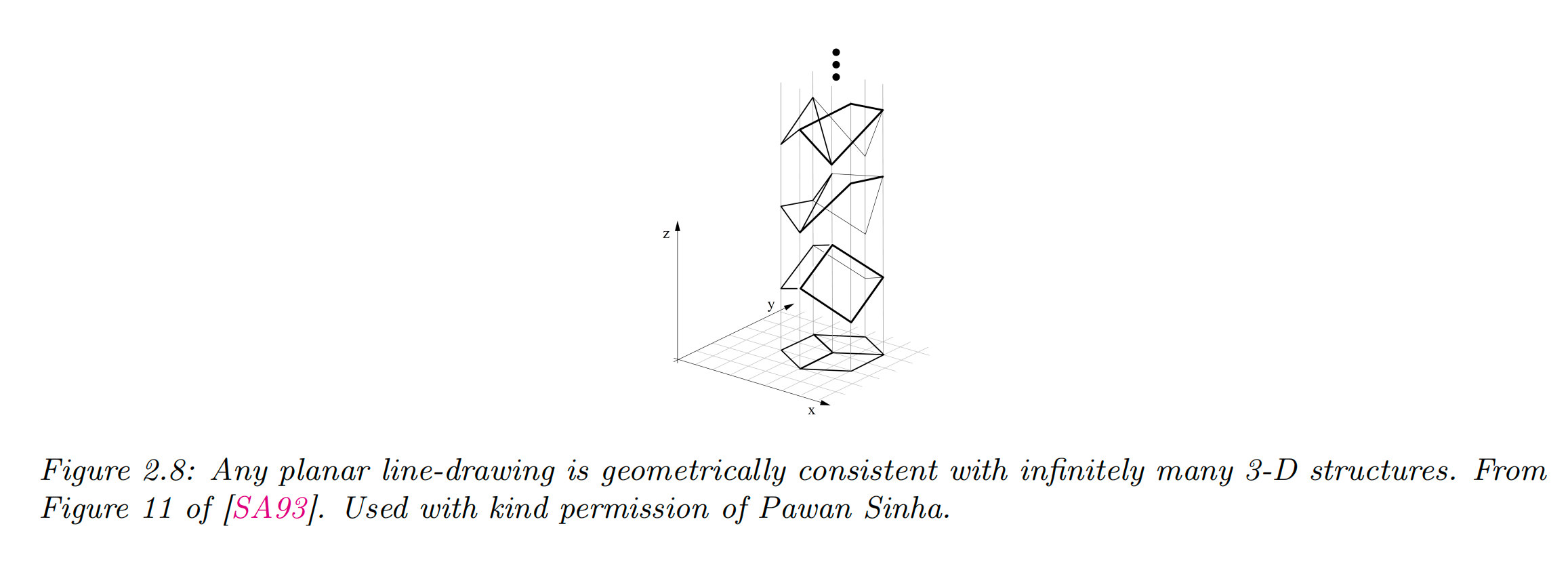
举个例子,设想我们要从一张二维图像
为了解决这类反向问题,我们可以使用贝叶斯公式来计算后验概率
要实现这一点,需要给出:
前向模型
先验分布
混合分布概率模型
混合模型的假设是:观测数据
公式:
其中:
整体
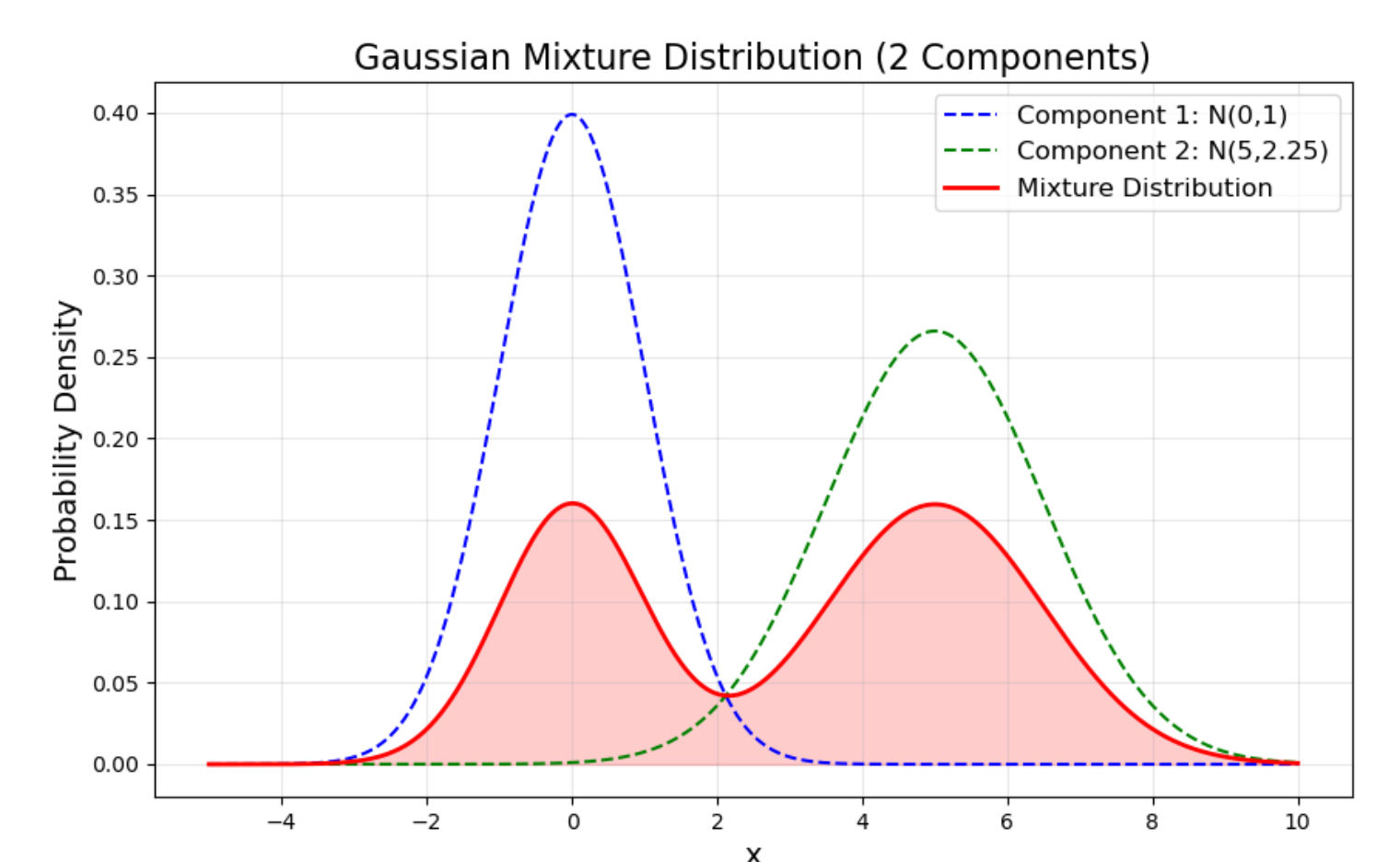
这里列举一个混合高斯分布的例子,我们设定了两个高斯分布:
成分1:均值
成分2:均值
最终的混合分布由这两个分布加权得到:
图中蓝色虚线是第一个高斯,绿色虚线是第二个高斯,红色实线就是它们的混合分布。
这相当于我们有两种“人群”——比如说一部分人身高在 170cm 左右(成分1),另一部分人身高在 180cm 左右(成分2),总人口分布就是这两类人混在一起的结果。这就是混合分布的意义。
在混合分布(Mixture Distribution)里,权重
比如在我举的例子里:
权重必须满足:
权重不是随便定的,它们一般通过 模型假设 + 数据估计 得到:
先验假设:有时我们事先知道(比如男女比例是 50/50),就可以直接设定。
参数学习:如果我们不知道比例,就用算法(通常是 EM算法)在数据上估计。
在 E 步:计算每个样本属于各个分布的“责任值”
在 M 步:根据这些责任值重新估计权重
一旦有了权重
这就是一个新的合法概率分布,可以直接用来:
绘图(像我画的红色曲线)
采样(先按权重选一个分布,再从那个分布里抽样)
计算概率(比如某个损失值出现的概率是多少)
为了更清晰地建模,通常引入一个 隐变量
条件分布
于是:
这就是混合分布的“生成过程”描述。
给定观测
这就是 贝叶斯公式。在标签噪声建模里,这个概率就对应 “一个样本是干净/噪声的可能性”。
期望最大化(Expectation-Maximization, EM)算法
在统计建模里,我们有一组观测数据
这就是 极大似然估计:
通常我们假设数据是 独立同分布(i.i.d.) 的,也就是说:
于是得到:
在混合分布模型中,单个样本的边缘概率是
所以完整似然就是:
混合模型的训练目标是 最大化似然:
直接优化很难,因为里面有求和。常见方法是 期望最大化(Expectation-Maximization, EM)算法:
E步(Expectation):计算后验概率
M步(Maximization):更新参数
更新混合系数:
更新成分参数
不断迭代 E-M,直到收敛。
高斯混合分布模型
高斯混合模型是一种 概率模型,用于对数据进行建模和聚类。它假设数据由 多个高斯分布(正态分布)混合而成,每个高斯分布代表一个潜在的子群体(cluster)。
数学上,GMM 可以写作:
其中:
核心思想:每个样本点
都有一定概率属于每个高斯分布(软聚类),而不是像 K-Means 那样直接划入某个簇(硬聚类)。
Beta 分布
Beta 分布是一类定义在 区间
其概率密度函数(PDF)为:
其中
参数含义
均值和方差为
特殊情况
- 当
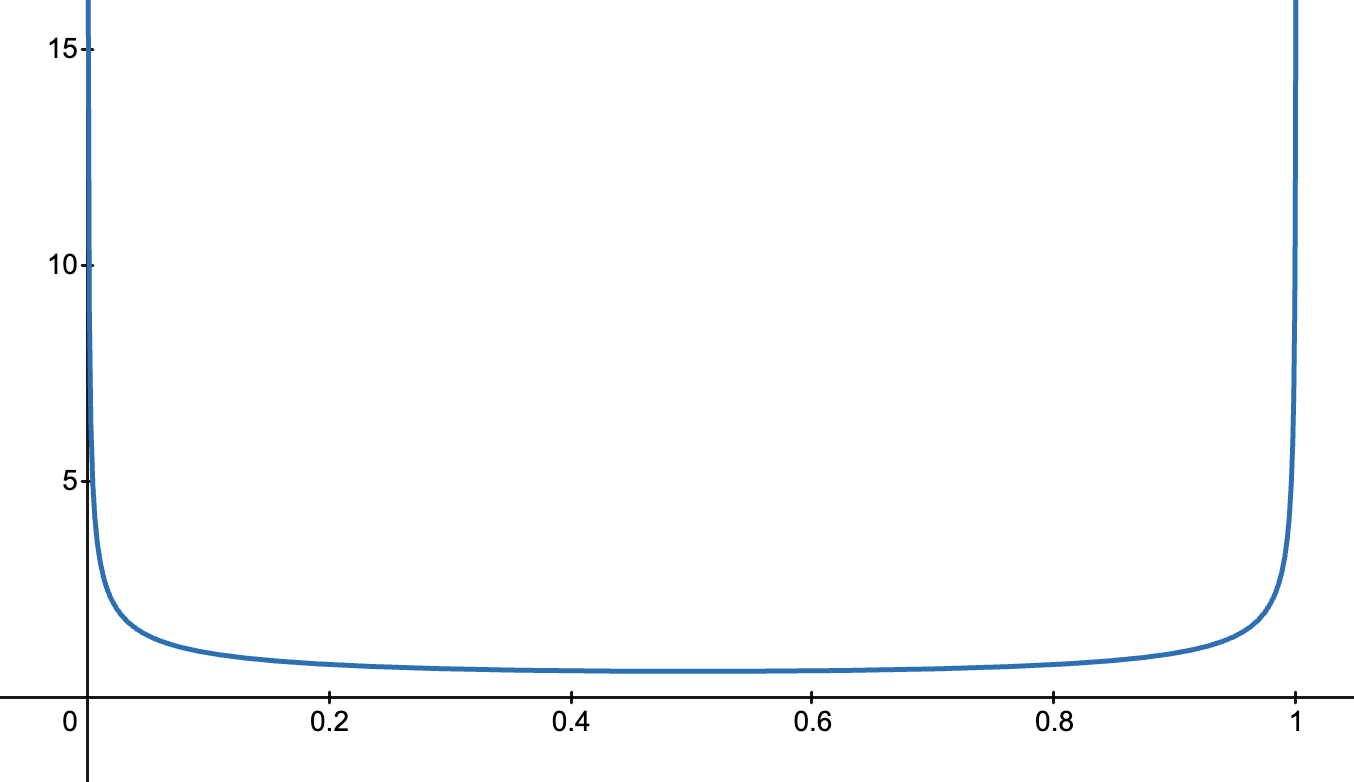
- 当
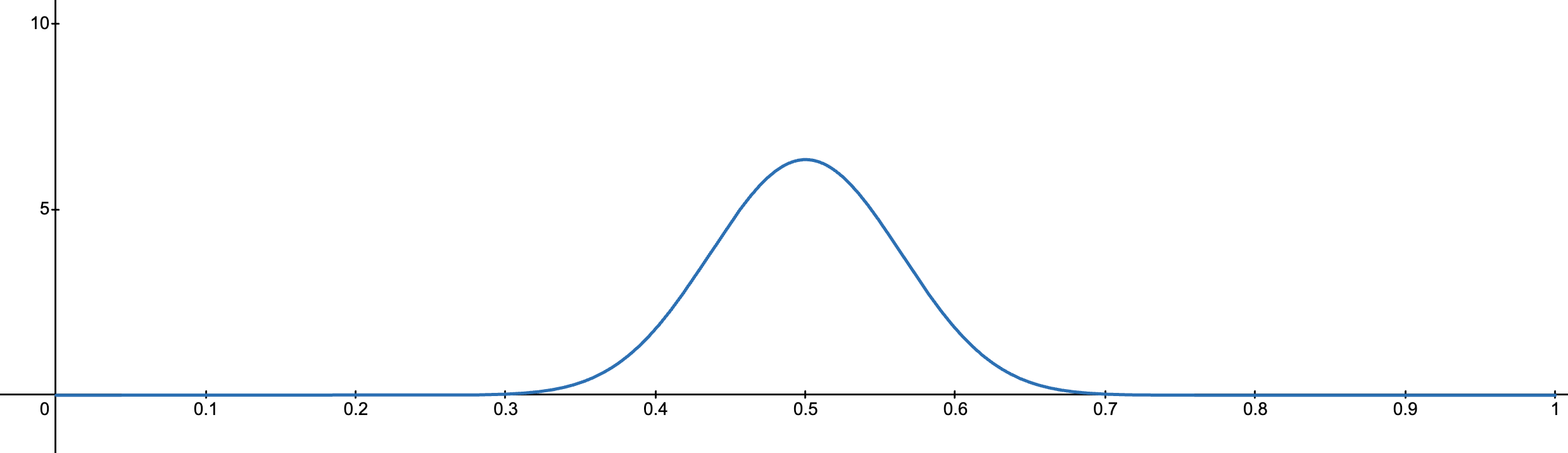
- 当
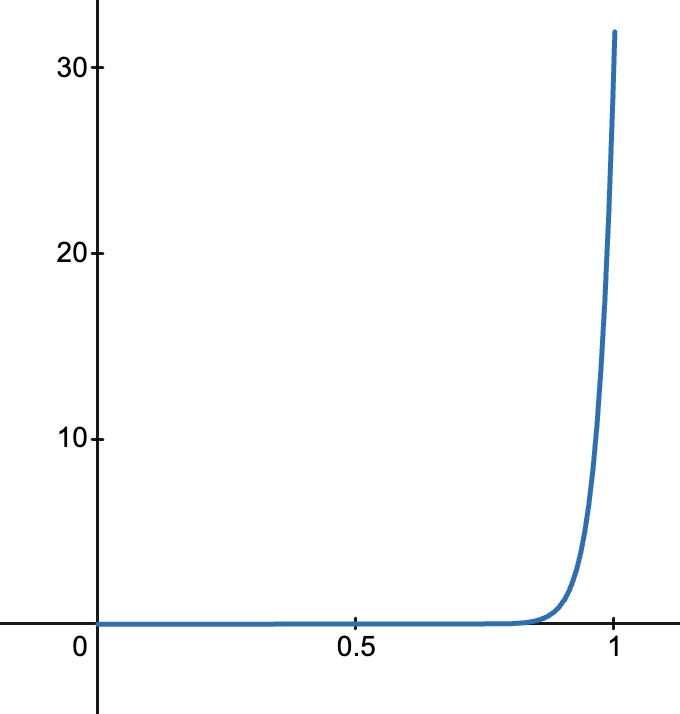
- 当
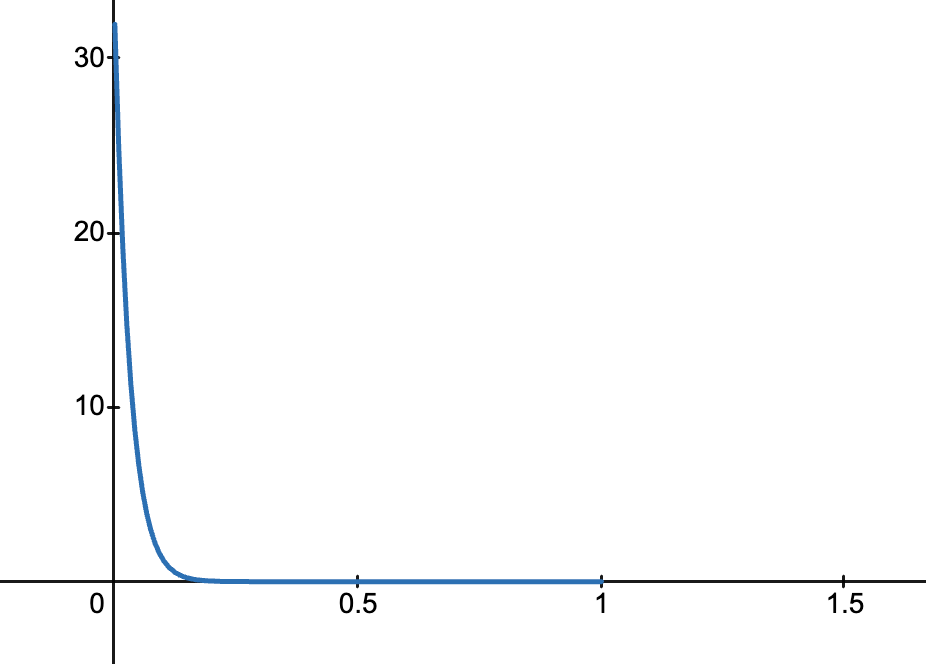
- 当
与二项分布/贝叶斯的关系
Beta 分布常被称为 二项分布的共轭先验。
如果我们有
假设成功概率
那么后验分布也是一个 Beta 分布:
这就是 Beta 分布在贝叶斯学习中的重要性。
Beta 分布的一个超能力是:用它作为二项分布的先验,看到数据之后,它的形式不变(还是 Beta 分布),只需要把参数加上观测次数就行,非常方便。
在机器学习中的应用
(1) 标签噪声建模
- 用 Beta 分布拟合样本损失的分布,可以区分「干净样本」和「噪声样本」。
(2) Mixup 数据增强
- 从
(3) 探索-利用问题(Bandit 问题)
- 在强化学习/多臂老虎机问题中,Beta 分布经常作为成功率的后验。
(4) 概率建模
- 因为 Beta 分布限制在
直观理解
可以把 Beta 分布看作是 “在 0 到 1 之间对概率值的信心”:
例如:
Beta 分布是定义在
互信息
互信息衡量 两个随机变量之间共享的信息量,也就是知道一个变量的信息后,能减少对另一个变量的不确定性多少。
直观理解:
如果两个变量完全独立,互信息为 0。
如果两个变量完全相关(知道一个就能确定另一个),互信息最大。
数学定义
设随机变量 (X) 和 (Y):
离散型:
连续型:
其中:
与熵的关系
互信息也可以表示为熵的形式:
其中:
互信息本质上是“减掉条件不确定性”的熵差。
特性
非负性:
对称性:
独立性:若
共轭先验
在贝叶斯统计中:
先验分布(Prior):表示在观察数据之前,对参数的信念。
似然函数(Likelihood):观测数据给定参数的概率。
后验分布(Posterior):观测数据后,参数的更新分布,根据贝叶斯公式:
共轭先验指的是:
如果选择某个先验分布,使得后验分布和先验分布属于同一分布家族,这个先验就叫共轭先验。
换句话说,共轭先验让 先验 + 数据 → 后验 的形式保持简单、同类。
直观理解
简单例子:投硬币
设投硬币概率 (p) 未知。
观测 (n) 次,得到 (k) 次正面:
如果选择 Beta 分布作为 (p) 的先验:
后验依然是 Beta 分布:
直觉:
Beta 分布“方便匹配”二项分布的形式,让更新后依然是 Beta。
这样计算后验和预测就非常简单,不需要复杂积分。
为什么重要
简化贝叶斯计算:后验易求解析解。
保持分布形式一致:便于连续更新数据。
在机器学习和统计建模中广泛应用,例如:
Dirichlet 是 Multinomial 的共轭先验(LDA 中常用)
Gamma 是 Poisson 的共轭先验
Normal 是 Normal(均值已知方差) 的共轭先验
共轭先验 = 选择一种先验,使得更新后(观测数据后)的后验分布依然属于同一个分布家族。
分布
多项分布(Categorical 分布)
定义:单次试验,选择
记法:
特点:
单次实验
输出是一个类别
特殊情况:当
多项式分布(Multinomial 分布)
定义:多次独立的 Categorical 试验的结果计数。
记法:
特点:
输出是一个计数向量 (
Categorical 是 Multinomial 的单次特例 (
公式:
特点:
输出是一个计数向量 (
Categorical 是 Multinomial 的单次特例 (
Beta 分布
定义:连续分布,用于建模 概率
记法:
特点:
支持单个概率参数的先验
是 Bernoulli/Binomial 分布的 共轭先验
公式:
Dirichlet 分布
定义:多维概率向量的分布,是 Beta 分布的多维推广。
记法:
特点:
支持概率向量 (
是 Multinomial 分布的 共轭先验
公式:
直觉:
Beta 分布对应 (K=2) 的 Dirichlet
Dirichlet 可以看作 Beta 分布在多类别上的推广
关系总结
| 分布类型 | 变量类型 | 实验次数 | 共轭先验 / 后验 |
|---|---|---|---|
| Categorical | 离散类别 ( | 1 | Dirichlet(K≥2) |
| Multinomial | 类别计数向量 ( | N | Dirichlet(K≥2) |
| Bernoulli | 二分类(0/1) | 1 | Beta |
| Binomial | 0/1 次数 | N | Beta |
| Beta | 概率 | — | — |
| Dirichlet | 概率向量 ( | — | — |
关键理解:
单次 vs 多次:
Categorical → 单次多项选择
Multinomial → 多次多项选择
一维 vs 多维:
Beta → 二分类概率的一维先验
Dirichlet → 多分类概率的多维先验
贝叶斯联系:
Beta 是 Bernoulli/ Binomial 的共轭先验
Dirichlet 是 Multinomial/ Categorical 的共轭先验
熵 ( H(A) ):信息的不确定性
熵(Entropy)度量了一个随机变量的不确定性程度,或说它平均能提供的信息量。
对于离散随机变量
熵越大,表示
熵越小,说明
熵的单位取决于对数底:
条件熵 ( H(A|B) ):已知 B 后 A 的不确定性
条件熵描述在已知随机变量
若
若
备注:
互信息 ( I(A;B) ):A 与 B 之间的“共享信息量”
互信息衡量随机变量
或等价地:
互信息 = “知道 B 能减少多少关于 A 的不确定性”, 越大表示 A、B 越“互相了解”。
条件互信息 ( I(A;B|C) ):给定 C 后,A 与 B 仍共享的信息量
条件互信息衡量在已知第三个变量
也可以写成对称形式:
这是在“排除掉
举例:
A :是否打伞
B :地面是否湿
C :是否下雨
若已知
马尔可夫链(Markov Chain)
设有三个随机变量
则称它们构成一个马尔可夫链:
也就是说:
在已知
的情况下, 对 没有额外的影响。
一旦知道
举一个直观例子:
| 随机变量 | 含义 |
|---|---|
| “晴天”或“下雨” | |
| 由天气决定 | |
| 由是否带伞决定 |
在这种情况下:
一旦知道“是否带伞 (
数据处理不等式(Data Processing Inequality, DPI)
如果随机变量
则有:
也就是说,信息在传递或加工过程中不会增加。
当信息从 A 经过 B 传递到 C 时,
你对 A 的了解只会减少或保持不变,不可能因为后续“加工”反而更清楚。
简单来说:
你不能通过后续的数据处理获得比原始数据更多的关于 A 的信息。
加工(processing)只能让信息丢失或保持,不可能“创造”额外的信息。
假设:
那么:
根据信息论:
说明:
经过压缩(B)→ 信息损失;
再经过滤镜(C)→ 信息进一步损失;
所以你从 C 中得到关于原图 A 的信息,不可能比从 B 得到的更多。
从互信息角度理解 DPI
互信息的定义:
DPI 表示:
也即:
→ “知道 B 后,A 的不确定性不会比知道 C 后更大。”
直觉:
B 比 C 更接近 A(因为 C 是由 B 产生的);
所以 B 对 A 的解释力更强。
推广与对称性
如果
对称形式的 DPI:
只要
单纯形
单纯形就是:在某个空间里,用最少数量的点连成的“最简单的形状”。
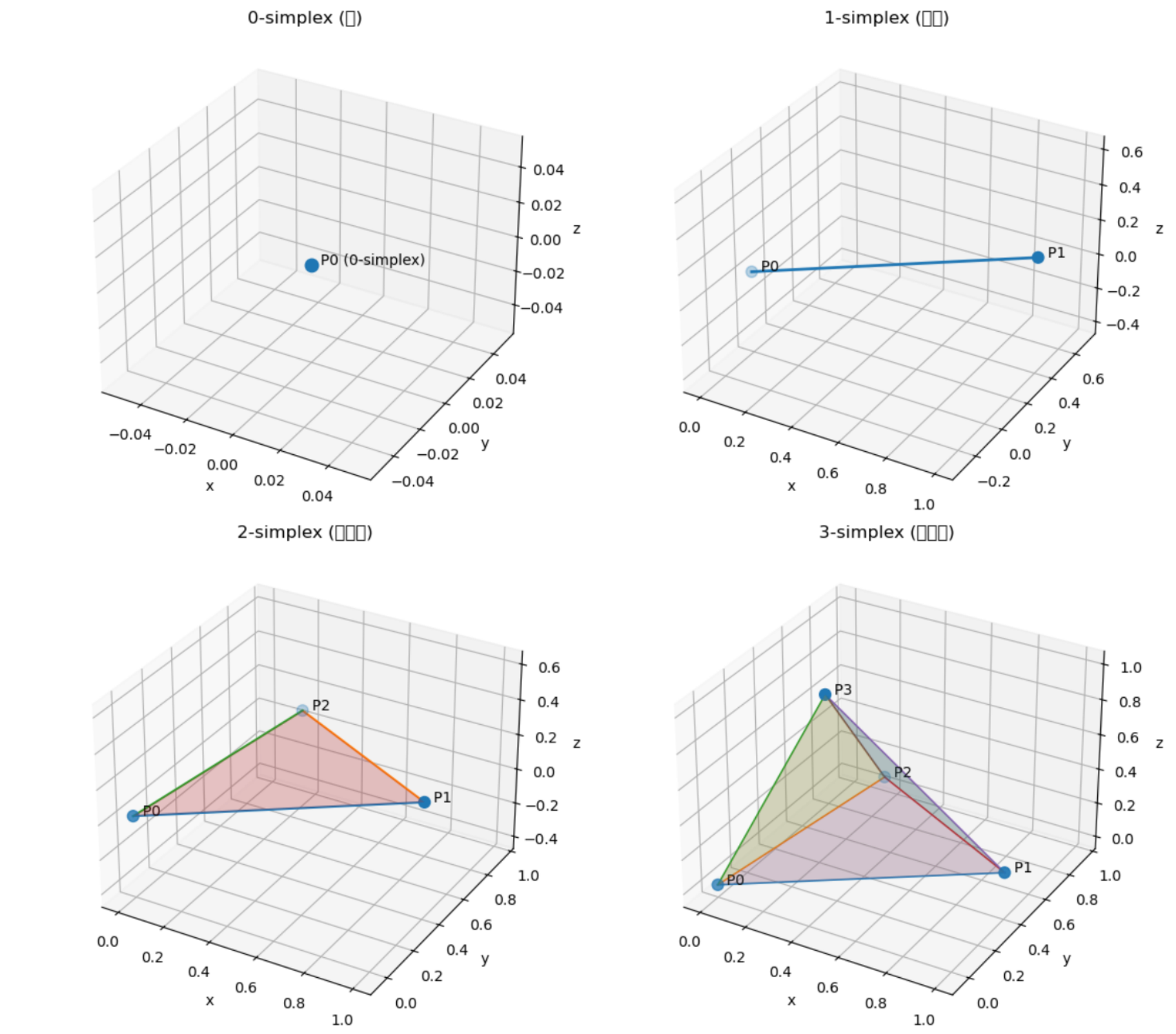
比如:
| 空间维度 | 最简单的形状 | 数学名字 |
|---|---|---|
| 0 维 | 点 | 0-单纯形 |
| 1 维 | 线段 | 1-单纯形 |
| 2 维 | 三角形(包括内部) | 2-单纯形 |
| 3 维 | 四面体(包括内部) | 3-单纯形 |
再往上推:
| 空间维度 | 对应的单纯形 |
|---|---|
| 4 维 | 五个点组成的“超四面体” |
| 5 维 | 六个点组成的“超超四面体” |
| n 维 | ( n+1 ) 个点组成的 n-单纯形 |
想象一下你在“造形状”:
如果你只有 一个点,你能造的最简单形状就是那个点。
加上第二个点 → 把它俩连起来 → 线段。
再加上第三个点,不要共线 → 你能围出一个最简单的面:三角形。
再加上第四个点,不要共面 → 你能围出一个最简单的体:四面体。
这就对应:
“1 维空间的最简单形状是线段,2 维的是三角形,3 维的是四面体。”
这就是单纯形的本质——最简单的凸形几何体。
一个单纯形,也可以理解为“几种东西按比例混合”的所有可能。
举个例子:
你有三种颜料:红、绿、蓝。
你用比例
👉 这个三角形,就是 2-单纯形; 再多一种颜料,就成了四面体(3-单纯形)。
所以单纯形也可以理解为:
“所有成分比例加起来为 1 的混合空间。”
这也是为什么在机器学习中,softmax 输出(所有概率加起来为 1)会落在一个单纯形上。
| 关键词 | 通俗解释 |
|---|---|
| 单纯 | 没有多余的结构,是最小的构造单位 |
| 形(simplex) | 形状、几何体 |
| 凸包 | “拉橡皮筋”包住几个点形成的形状 |
| 维数 | 由多少个互不在同一平面上的点构成减一 |
| 重心坐标 | 在形状内部,一个点由各顶点“按比例拉扯”而成的权重 |
单纯形(simplex)就是“用最少数量的点,在空间中撑起来的最简单的几何形状”。
在 3D 里,它就是一个四面体。
单纯形与Dirichlet分布的关系
对于
我们通常有一个类别概率向量
其中满足:
所有这样的
Dirichlet 分布就是一个定义在
也就是说:
它告诉我们——“一个概率向量
(即一组类别概率)出现在单纯形上某个区域的可能性有多大”。
换句话说:
Dirichlet 分布建模的正是单纯形上“各个点的分布情况”。
Dirichlet 分布的概率密度函数为:
其中:
每个
因此:
Dirichlet 分布是一个在
维单纯形上的密度函数,而不是在整个 空间中的密度函数。
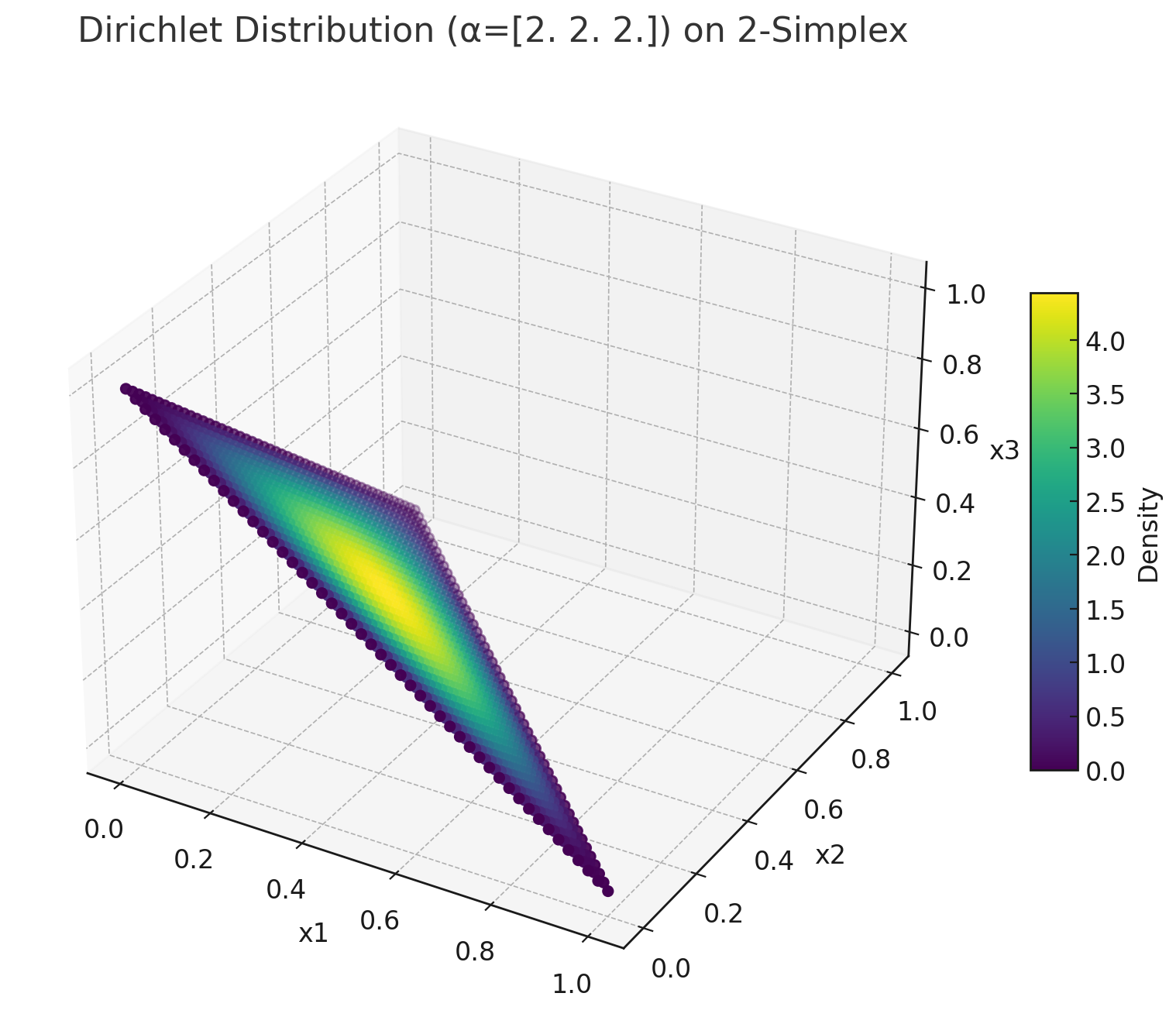
当
条件
定义域是二维平面上的一个三角形(2-simplex)。
Dirichlet 分布此时定义在这个三角形上,
即:
三角形中每一个点代表一个可能的概率分布
,
Dirichlet 分布给出了这些点出现的概率密度。
如果我们绘制 Dirichlet 分布的图,就可以看到不同的
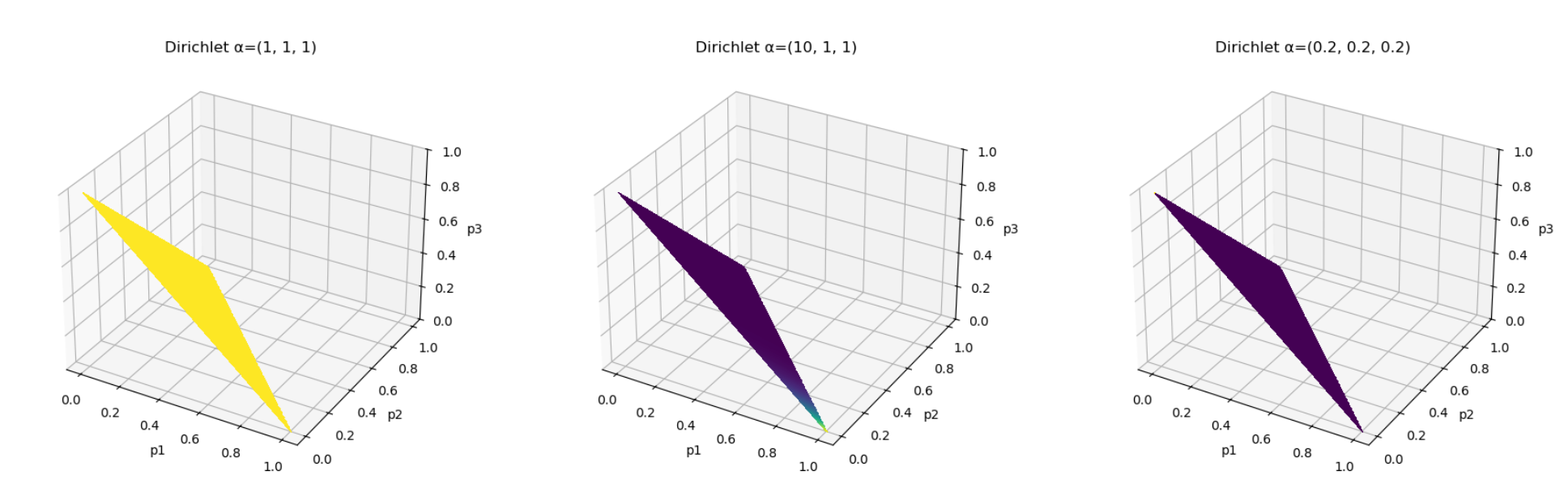
| 概念 | 含义 |
|---|---|
| 2-simplex | 满足 |
| Dirichlet 分布 | 在该三角形上定义的概率密度函数 |
| 每个点 | 一个合法的三分类概率分布 |
| Dirichlet 的任务 | 给出“哪些 |
泛化误差上界
在统计学习理论中,泛化误差上界(generalization error bound) 通常写作一个由 三部分组成 的表达式:
下面详细解释这三项的含义与作用:
经验误差(Empirical Error / Training Loss)
也称为经验风险 (
意义:衡量模型在已知样本上的拟合程度;
越小越好,但过小可能意味着过拟合。
复杂度项(Complexity Term)
我们希望学习到的模型
真正关心的是 泛化误差(generalization error):
但我们无法直接计算它,只能用有限样本近似:
问题:
如果我们只最小化经验误差(即 ERM:Empirical Risk Minimization), 模型可能会完美拟合训练集(训练误差趋近于0),但在测试集上表现很差 —— 这就是过拟合(overfitting)。
→ 所以我们需要一个“惩罚项”,衡量模型过于复杂时带来的风险。
复杂度项的数学动机
在统计学习理论中,我们希望找到这样一个高概率不等式:
这个“惩罚项”反映了模型在有限样本下的不确定性:
样本太少、模型太复杂,就可能把“噪声”当作“信号”。
举个直观的例子👇
| 模型 | 自由度 | 拟合训练集的能力 | 泛化风险 |
|---|---|---|---|
| 线性模型 | 小 | 拟合能力弱 | 稳定 |
| 高次多项式 | 大 | 拟合能力强 | 容易过拟合 |
| 神经网络(参数巨多) | 极大 | 可零训练误差 | 泛化风险最高 |
在这种情况下,复杂度项能让上界反映出这种差别:
简单模型 → 复杂度项小 → 上界紧 → 泛化好
复杂模型 → 复杂度项大 → 上界松 → 泛化差
从不同理论角度看“复杂度项”
| 理论框架 | 复杂度项的本质 | 含义 |
|---|---|---|
| VC维理论 | 与模型空间的VC维 | 模型能区分样本的能力 |
| Rademacher复杂度 | 模型拟合随机噪声的能力 | 衡量模型的灵活度 |
| PAC-Bayes界 | KL散度 | 衡量后验分布偏离先验的程度 |
| 信息论视角 | 压缩描述长度 | 模型“信息量”的大小 |
换句话说: 复杂度项是用来“惩罚过高的模型自由度”,从而在偏差-方差之间取得平衡。
总结一句话
复杂度项的存在,是为了保证泛化能力的上界可控。
经验误差 → 追求拟合训练集
复杂度项 → 防止模型过度复杂
两者平衡 → 才能实现真正的“好模型”
常数项
常数项来源于样本抽取的随机性,即训练集只是从真实分布中随机采样得到的一个有限集合。由于这种随机性,经验误差与真实泛化误差之间会存在波动。
通过 Hoeffding 不等式可得:
推出:
这个项就是常数项。
常数项仅依赖于样本数量
泛化界中的
这里的
泛化上界可能不成立的概率。
也就是说:
以至少
以最多
换句话说,
结果为 5.0 ± 0.1,置信度 95%。
这里“95%”其实就是
我们有 95% 的把握认为真值落在 [4.9, 5.1] 之间。
在泛化界里,意思完全一样: 我们不是说“上界一定成立”,而是说“它几乎肯定成立”。
数学来源:概率不等式中的“置信参数”
在推导泛化界时,我们通常用到统计学中的浓缩不等式(concentration inequality),例如 Hoeffding 不等式:
令右边等于
这就是常数项中常出现的那部分:
所以:
当你选取更小的
→ 表示你想要更高的置信度(99% 成立);
→ 但界会更“宽”(常数项变大)。
当你取较大的
→ 表示你允许更大概率的失败(只要求90%成立);
→ 界更“紧”(常数项变小)。
的实际意义:置信度与保守性权衡
| 取值 | 含义 | 影响 |
|---|---|---|
| 上界有 90% 的概率成立 | 常数项较小,上界紧但不太稳 | |
| 上界有 99% 的概率成立 | 常数项变大,上界更保守 | |
| 上界几乎总成立 | 常数项巨大,上界非常松 |
因此:
控制的是“上界可靠性”和“上界紧致度”之间的平衡。
在实际理论分析或论文中,研究者通常取:
对应 95%~99% 的置信度; 总结一句话
是“泛化界成立失败的概率上限”,
它控制了泛化误差上界的“置信度”与“保守程度”。
取值越小 → 置信度越高 → 上界越宽。
取值越大 → 置信度越低 → 上界越紧。
多模态场景
多模态学习引入了额外的不确定性来源(模态相关、分布偏移、信息交互等),因此其泛化误差上界中会比单模态多出“额外项”,这些项用于量化模态间依赖、噪声和对齐偏差对泛化能力的影响。