
概率论基础概念(用到多少,学多少 =_=)
概率空间
我们将概率空间定义为三元组
离散随机变量
最简单的情况是实验的结果是可数的。例如,掷一个三面骰子,其三个面分别标记为 “A”、“B”、“C”(为了简洁,我们用3面而不是6面)。此时:
样本空间为
事件空间为
其中每一个事件就是事件空间中的一个元素。例如:
事件
事件
定义事件空间后,需要指定概率度量
则复合事件的概率可通过求和得到,例如:
为简化记号,我们可以将每个样本空间中的结果映射为一个实数,这就定义了随机变量(random variable,记作 rv):
随机变量 = 一个把“事件结果”映射为“数值”的函数,它本身不随机,随机的是它作用的输入(样本
)。
例如,对三面骰子设:
再如,掷两次公平硬币,样本空间为:
设随机变量
我们将随机变量可能的取值集合称为其状态空间,记作
其中
你有一个随机变量
,它是一个函数,从样本空间 映射到实数;给定某个输出值 ,我们关心的是:随机变量等于这个值的概率是多少,即 。
但是:随机变量是函数,它本身不“随机”,真正随机的是实验结果。所以,要知道“ ”的概率是多少,其实等价于问:
- 有多少个
会导致 ,而这些 的总概率是多少?
所以,我们这么定义:
:是所有让 成立的样本点集合(这就是“原像”); - 然后,
:就是计算这些 的总概率。
实验:投两次硬币
定义随机变量
:表示正面(H)的次数
现在我们问:
这等价于找出:
哪些
会导致 ? 答案是
如果每个
的概率都是 ,那么:
这里,
pmf 可用柱状图表示,也可用参数化函数表示。我们称
随机变量
把世界事件映射成数字;
pmf把这些数字映射成它们发生的概率。
连续随机变量
我们也可以考虑结果为连续值的实验。这种情况下,假设样本空间是实数集合的子集:
例如,测量某事件持续时间(单位:秒),设:
由于该集合是不可数的,无法像离散情形那样枚举所有子集。因此,我们需要借助Borel σ-代数(Borel sigma-field)来定义事件空间。其定义如下:
集合
若
若
Borel σ-代数是由半开区间
当我们讨论连续型随机变量(比如测量一个时间、距离或温度)时,它的样本空间是连续的,比如:
在这种连续的空间里,所有可能的“事件”不是像离散情况那样简单地枚举出来的(比如
),而可能是“无限多种可能的区间组合”。
比如我们可能想表示这些事件:
“温度在 1 到 2 度之间” → 区间 (1, 2)
“时间小于 5 秒” → 区间
“温度是 3 度或 7 度” →
“测量值是无理数” → 这也算是一类事件!
但是问题是:我们不能对“所有”这样的集合都定义概率!
因为某些集合太“奇怪”或太“复杂”,会导致概率的定义出现矛盾或不收敛。
所以我们需要一个规则体系来规定“我们只对哪些集合定义概率” ——> 这个规则体系就是σ-代数(sigma-field)。
σ-代数是一个集合的集合(简单理解:是你允许讨论的事件的全集合),它必须满足以下三条规则(你可以把它们理解成“合理事件空间”的要求):
包含整个样本空间和空集
- 你总得允许“什么都不发生”(空事件)
- 也得允许“一定会发生”(整个样本空间)
如果你能谈某个事件,那它的补集你也得能谈
- 比如:“温度小于 30 度” 这个事件存在,那“温度不小于 30 度”这个事件也应该存在
如果你能谈一堆事件,那它们的并集和交集也得能谈
- 比如你能谈“温度在 (0,1)”、“温度在 (1,2)”……,那“温度在 (0,2)”这种组合你也得能谈
换句话说:σ-代数就是一种封闭的事件系统,允许你用基本事件构造更复杂事件,但不会跑出系统之外。
Borel σ-代数是专门为实数空间()设计的一种 σ-代数,用来处理实数范围内的“正常”区间事件。
它的定义是:
Borel σ-代数是由所有形如的区间生成的最小 σ-代数。
也就是说,它从一些基本的“区间事件”出发,通过反复地做并集、交集、补集操作,构造出你所需要的所有“常见事件”。
比如:
:开区间
:闭区间
、 :半开区间
:单点集 任意有限/可数个区间并集交集……
这些都属于 Borel σ-代数。
你可以把它理解成:我们定义概率,只在这些“结构正常的区间组合”上做,不碰那些太反直觉或病态的集合。
总结: Borel σ-代数是一种你可以安全地讨论概率的“事件集合体系”,它由一些基本区间(比如)出发,闭包得到所有“常规可测的集合”。
在持续时间的例子中,可进一步限制事件空间只包含区间
为定义概率度量,我们为每个
对于事件
还可以定义累积分布函数(cdf):
从中可以计算区间概率:
“概率分布”一词既可以指 pdf
上述定义也可推广到多维空间
概率公理
与事件空间相关联的概率规律,必须遵循概率公理(Kolmogorov 公理),具体如下:
非负性(Non-negativity):
对任意事件
规范性(Normalization):
整个样本空间的概率为 1:
可加性(Additivity):
对于任意一列两两互不相交(即互斥)的事件
在有限的情况下,比如只有两个互斥事件
这个公式对应的是“事件
从这些公理可以推导出一些常用结论:
补集规则(Complement Rule):
其中,
这个结论来自于:
其他可推出的结论:
加法规则(Addition Rule):
对于任意两个事件(不要求互斥),有:
这个公式适用于任意两个事件,即使它们可能有重叠。
条件概率
考虑两个事件
根据这个定义,可以得到乘法法则(multiplication rule):
条件概率衡量的是:在事件
然而,如果两个事件是无关的,那么一个事件的发生不会改变另一个事件的概率。更形式化地说,若满足以下条件,则称
若
同理,若在某个事件
则称
全概率公式(Law of total probability)
根据条件概率的定义,还可以推导出全概率公式:
若集合
全概率公式: 一个事件总体概率 = 在不同情形下它发生的概率 × 各种情形本身的概率,加起来。
假设我们有一个检测疾病的筛查工具,我们要问:
- 一个人检测为阳性的总体概率是多少?
我们知道:
人群中 1% 有病(记作
),99% 无病(记作 ); 如果有病(
),检测为阳性( )的概率是 0.9(即 ); 如果没病(
),误报为阳性概率是 0.05(即 );
问:一个人检测阳性的总体概率是多少?
我们把“人是否患病”作为划分事件:
:患病,
:未患病,
我们要算的事件是“检测为阳性”(
): 所以,虽然你可能觉得“阳性概率应该很高”,但实际上总体阳性概率只有 5.85%,因为大多数人根本没病,而没病的人也有误报。
贝叶斯法则
根据条件概率的定义,可以推导出贝叶斯法则(Bayes’ rule),也称为贝叶斯定理(Bayes’ theorem)。对于任意两个满足
离散随机变量形式
对于一个具有
其中:
连续随机变量形式
对于一个连续型随机变量
这就是贝叶斯法则在离散和连续两种情形下的表达方式,它提供了一种根据观测数据(事件
一些常见的概率分布
在构建各种类型的模型时,我们会用到多种概率分布。以下小节总结了其中一些常见分布。
交互式可视化网站: 🔗 https://ben18785.shinyapps.io/distribution-zoo/
离散分布
本节讨论的是定义在(非负)整数子集上的一些离散型概率分布。
伯努利分布与二项分布(Bernoulli and Binomial distributions)
设
其中,
如果
其中,
分类分布与多项分布(Categorical and Multinomial distributions)
如果变量是多值离散型的(例如
其中
或者,也可以将 K 类变量
其中
如果
其中,多项系数(multinomial coefficient)定义为:
泊松分布(Poisson distribution)
设随机变量
其中,
负二项分布(Negative binomial distribution)
假设我们有一个“盒子”(或称“容器”)中有
我们进行有放回抽样,直到抽出
即:
转换视角:定义失败为红球,成功为蓝球
现在我们重新定义抽红球为“失败”、抽蓝球为“成功”。我们继续抽球,直到观察到
设
也就是说,
其中
组合数
这表示从次试验中选出 次成功的位置,剩下的是失败。
这里试验顺序重要,且第次失败必须是第 次试验的结果(最后一次失败)。
二项分布关注试验次数固定,成功次数随机。
负二项分布关注成功次数固定,试验次数(失败次数)随机。
特殊情况说明
如果
利用了恒等式
数学期望与方差
负二项分布的两个矩(均值和方差)为:
负二项分布的意义与优势
这种含有两个参数的分布比泊松分布更具有建模灵活性,因为它可以单独控制均值与方差。这在模拟某些“传染性事件”时非常有用,例如某些事件之间是正相关的,它们的出现会导致比独立情形更大的方差。
事实上,泊松分布是负二项分布的一个特例。可以证明:
另一个特例是当
定义在实数上的连续分布
在本节中,我们讨论一些定义在实数集合
高斯分布(正态分布)
最广泛使用的一元分布是高斯分布(Gaussian distribution),也叫正态分布(normal distribution)。
高斯分布的概率密度函数(pdf)定义为:
其中,
参数
参数
有时我们也会讨论高斯分布的精度(precision),即方差的倒数:
精度越高意味着分布越“窄”(即方差小),集中在
高斯分布的累积分布函数(cdf)定义为:
如果
半正态分布(Half-normal)
在某些问题中,我们希望使用定义在非负实数上的分布。一种构造这类分布的方法是设定:
由此诱导出的
这个分布可以被看作是标准正态分布
学生 t 分布(Student t-distribution)
高斯分布的一个问题在于它对离群点非常敏感,因为其概率密度随着与中心的平方距离增大而指数级衰减。一种更具鲁棒性的分布是 学生 t 分布(Student t-distribution),我们简称为Student 分布。它的概率密度函数(pdf)如下:
其中:
归一化常数
这里:
柯西分布(Cauchy distribution)
当
其中:
这个分布的一个显著特点是:它的尾部非常厚重(heavy tails),以至于定义均值的积分并不收敛(即没有期望值)。
半柯西分布(half Cauchy distribution) 是一种基于均值为 0 的柯西分布进行“折叠”的版本,也就是说,它的概率密度函数全部集中在正实数轴上。
因此,其形式为:
更多分布使用到的时候再进行补充
高斯联合分布(Gaussian joint distributions)
对于连续型随机变量,使用最广泛的联合概率分布是多元高斯分布(multivariate Gaussian 或 multivariate normal,简称 MVN)。
这种分布之所以受欢迎,一方面是因为其数学处理非常方便,另一方面在许多实际问题中,高斯分布作为近似是相当合理的。事实上,在给定均值和协方差矩的约束下,高斯分布是熵最大的分布。鉴于它的重要性,本节将详细讨论高斯分布。
多元正态分布(The multivariate normal)
在本节中,我们将详细介绍多元高斯分布,又称多元正态分布(MVN)。
定义(Definition)
多元高斯分布的概率密度函数定义如下:
其中:
归一化常数
指数中的表达式(忽略系数 -0.5)是数据向量
在二维空间中,多元高斯分布被称为二维高斯分布(bivariate Gaussian distribution)。其概率密度函数可表示为:
协方差矩阵形式为:
其中:
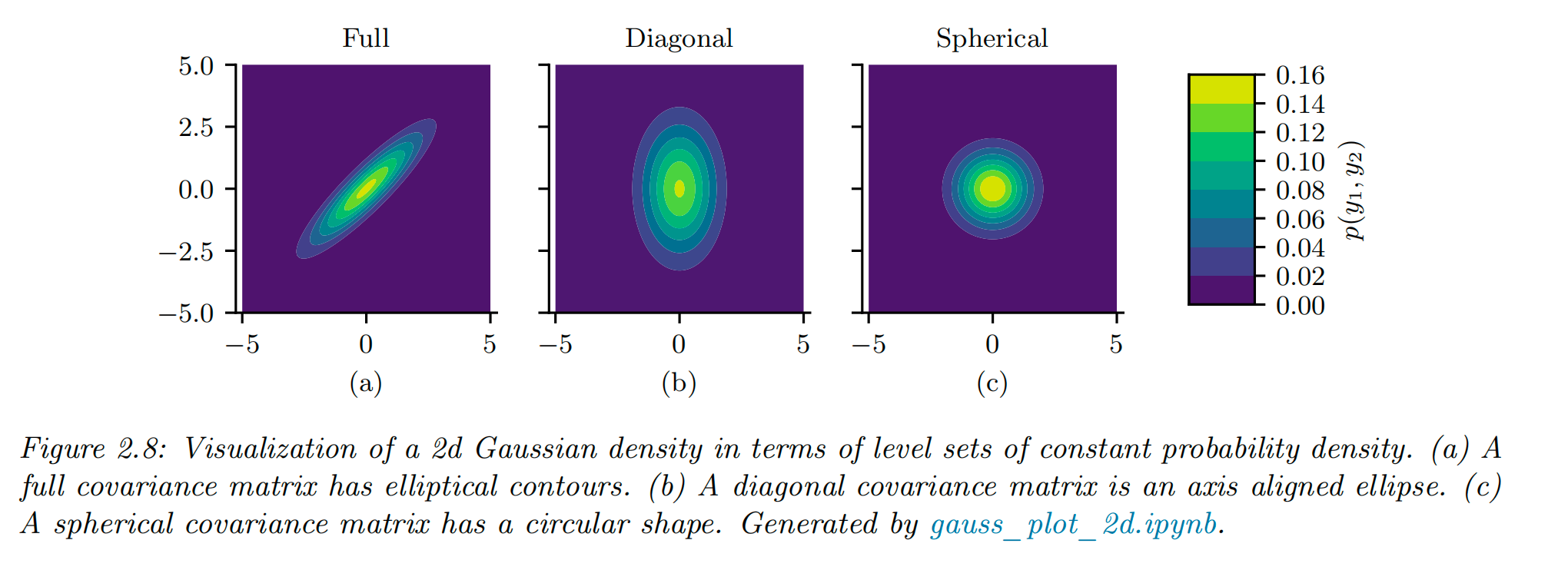
图 2.8 展示了三种不同协方差矩阵下的二维多元高斯密度图:
完全协方差矩阵(Full covariance matrix): 有
对角协方差矩阵(Diagonal covariance matrix): 只有 D 个自由参数,非对角线元素为 0,表示变量之间不相关。
球形协方差矩阵(Spherical covariance matrix): 也称为各向同性协方差矩阵(isotropic covariance matrix),只有一个自由参数
只有一个自由参数
当然可以,以下是你提供内容的逐段翻译与解释,保持原意清晰、结构一致:
高斯壳(Gaussian shells)
在高维空间中,多元高斯分布的行为可能会显得非常反直觉。我们可以提出这样一个问题:
如果我们从
中采样,其中 是维度数,我们应该预期这些样本大多会落在空间的哪里?
由于概率密度函数的峰值(众数)位于原点
然而,在高维空间中,高斯分布的“典型集合(typical set)”实际上是一个很薄的壳层或环带,其:
与原点的距离为:
壳层的厚度为:
直观解释如下:
虽然密度函数以
球体的体积随半径
因为概率质量 = 密度 × 体积;
所以,两者之间会出现一种“相互抵消的平衡点” —— 也就是在某个距离范围内,虽然密度在下降,但体积增加更快;
大多数样本会集中在这个区域上 —— 也就是所谓的“高斯肥皂泡现象(Gaussian soap bubble phenomenon)”。
数学解释:为什么高斯样本集中在壳层上?
考虑某个点
期望平方距离为:
方差为:
相对标准差(变异系数)为:
这意味着:
尽管每个样本的距离是随机的;
但当维度
从而,距离本身越来越集中在
这就是为什么我们说样本会集中在距离原点约为
图像空间的含义(例如灰度图像)
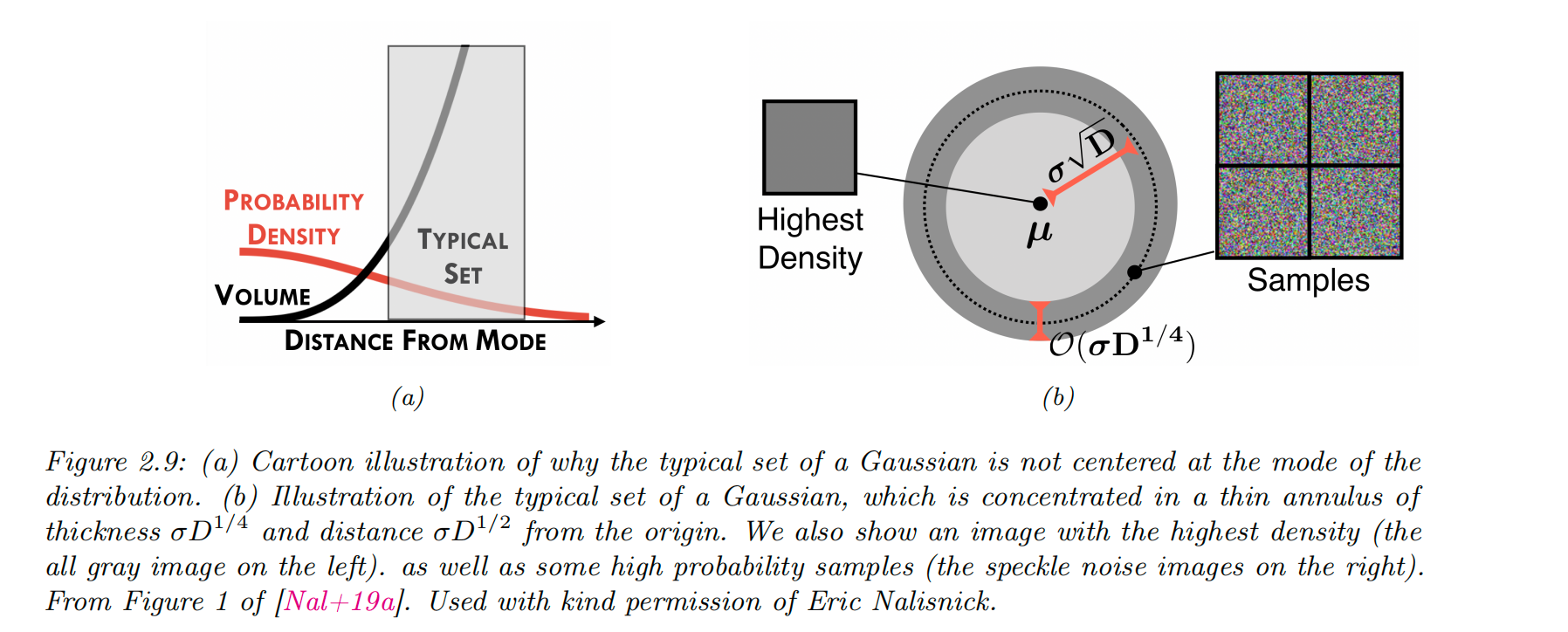
图 2.9b 展示了一些从如下高斯分布中采样的灰度图像:
其中
你可能以为既然是围绕全灰图采样,那么采样出来的图像应该也接近灰色。但事实恰恰相反:
在高维图像空间中,几乎不可能采样到接近灰色的图像。
这是因为样本几乎全部落在离