
深度学习中常见API记录
Python
位置参数与关键字参数
位置参数(Positional Argument):按 位置顺序 传入函数的参数。
关键字参数(Keyword Argument):用 key=value 的形式明确指定的参数。
| 场景 | 位置参数 * | 关键字参数 ** |
|---|---|---|
| 调用时 | 解包 tuple/list | 解包 dict |
| 定义时 | 收集成 tuple | 收集成 dict |
闭包与高阶导数
什么是高阶函数?
高阶函数(Higher-Order Function)满足以下两个条件之一即可:
函数接收另一个函数作为参数;
函数返回一个函数。
Python 中的 map、sorted、functools.partial 都是高阶函数。
比如这个函数就是高阶函数:
def outer(func): # 接收函数作为参数
def inner():
print("调用前")
func()
print("调用后")
return inner # 返回一个函数什么是闭包?
闭包是一个函数,它“记住”了它定义时的 外部作用域变量,即使外部函数已经执行完毕,这些变量依然存在。
例如:
def outer():
x = 10
def inner():
print(x) # inner 记住了 x
return inner
f = outer()
f() # 输出 10这里 inner 是一个闭包,因为它引用了 outer 中的变量 x,而 outer 已经返回了。
正常情况下:局部变量会在函数执行完后被释放; 但如果我们在内部函数中引用了外部函数的变量,Python 会自动把这些变量“绑定”到这个内部函数上,也就是形成闭包, 变量“被引用”而不会释放。
装饰器的实现用到了什么?
现在看一个典型的装饰器例子:
def my_decorator(func): # ✅ 高阶函数(接收函数并返回函数)
def wrapper(*args, **kwargs): # ✅ wrapper 是闭包(记住了 func)
print("Before call")
result = func(*args, **kwargs)
print("After call")
return result
return wrapper
@my_decorator
def greet(name):
print(f"Hello, {name}")my_decorator是 高阶函数,因为它接收func并返回wrapper。wrapper是 闭包,因为它访问了其外部作用域的变量func,并在被调用时依然保留这个引用。
“装饰器 = 高阶函数 + 闭包” 的意思是:
一个装饰器的实现,必须用高阶函数(来接收和返回函数),而在返回的内部函数中,依赖闭包机制来记住原函数的引用,从而实现对原函数行为的增强或修改。
装饰器
装饰器是 Python 中的一种语法结构,本质是一个 函数(或类),它接收一个函数或类作为参数,对其进行加工,并返回一个新的函数或类对象。
简而言之:
装饰器 = 高阶函数 + 闭包
装饰器主要用于在 不修改原始函数代码的前提下,动态增加其功能,这在日志记录、性能测试、权限校验等场景中非常常见。
最基本的函数装饰器
def my_decorator(func):
def wrapper():
print("调用前")
func()
print("调用后")
return wrapper
@my_decorator
def say_hello():
print("Hello")
say_hello()输出:
调用前
Hello
调用后说明:
@my_decorator相当于:say_hello = my_decorator(say_hello)wrapper()是闭包,持有对func的引用。- 返回的
wrapper函数替代了原来的say_hello函数。
带参数的函数装饰器
装饰器支持原函数有参数的情况:
def my_decorator(func):
def wrapper(*args, **kwargs):
print("开始")
result = func(*args, **kwargs)
print("结束")
return result
return wrapper
@my_decorator
def add(a, b):
return a + b
print(add(3, 5))使用
*args和**kwargs是为了支持任意参数签名。
带参数的装饰器(装饰器工厂)
如果你希望装饰器 本身接受参数,则需要再多一层函数嵌套:
def log(prefix):
def decorator(func):
def wrapper(*args, **kwargs):
print(f"{prefix} 开始调用 {func.__name__}")
result = func(*args, **kwargs)
print(f"{prefix} 结束调用 {func.__name__}")
return result
return wrapper
return decorator
@log("DEBUG")
def multiply(a, b):
return a * b执行顺序:
@log("DEBUG")先返回decorator- 然后
decorator(multiply)返回wrapper
使用 functools.wraps 保留原函数元信息
装饰器会改变函数的元信息:
def my_decorator(func):
def wrapper(*args, **kwargs):
print("Before call")
return func(*args, **kwargs)
return wrapper
@my_decorator
def greet(name):
"""Say hello to someone"""
print(f"Hello, {name}")
print(greet.__name__) # ⚠️ 输出 wrapper,不是 greet
print(greet.__doc__) # ⚠️ 输出 None,不是函数原文档@my_decorator 返回的是 wrapper 函数,所以 greet 实际上变成了 wrapper,它的名字和文档字符串也被覆盖了,所以使用装饰器会导致原函数的 __name__、__doc__ 等属性丢失。
Python 提供了 functools.wraps(func) 装饰器,作用是:
- 把原函数的
__name__、__doc__、__module__等元信息“复制”到 wrapper 函数上,让被装饰函数看起来仍然像原来的函数。
import functools
def my_decorator(func):
@functools.wraps(func) # ✅ 这一步很关键
def wrapper(*args, **kwargs):
print("Before call")
return func(*args, **kwargs)
return wrapper
@my_decorator
def greet(name):
"""Say hello to someone"""
print(f"Hello, {name}")
print(greet.__name__) # ✅ greet
print(greet.__doc__) # ✅ Say hello to someone这在调试、文档生成、类型检查、元编程、反射中都非常重要。例如:
help(greet):没有 wraps 就看不到真实文档了
使用 inspect 模块查看参数、注解、类型签名会失效
多个装饰器嵌套时更容易出错
装饰类方法(普通方法 / 类方法 / 静态方法)
def log_method(func):
@wraps(func)
def wrapper(*args, **kwargs):
print(f"调用方法 {func.__name__}")
return func(*args, **kwargs)
return wrapper
class MyClass:
@log_method
def hello(self):
print("Hello from method")装饰整个类
def decorate_class(cls):
cls.version = "1.0"
return cls
@decorate_class
class MyService:
pass
print(MyService.version) # 1.0装饰器的底层原理与执行过程
本质:装饰器 = 函数替换器
一个装饰器:
@decorator
def func():
pass等价于:
func = decorator(func)即:把 func 传给 decorator 函数,并用它的返回值替换 func 本身。
多个装饰器叠加时的执行顺序(从内到外)
@d1
@d2
def func():
pass等价于:
func = d1(d2(func))即,先应用最内层的 d2,再由外层 d1 包裹起来。
类装饰器
类装饰器通常通过实现 __call__ 方法来模拟函数行为:
class MyDecorator:
def __init__(self, func):
self.func = func
def __call__(self, *args, **kwargs):
print("调用前")
result = self.func(*args, **kwargs)
print("调用后")
return result
@MyDecorator
def greet(name):
print(f"Hi, {name}")
greet("Alice")总结
| 类型 | 例子 | 含义 |
|---|---|---|
| 最基本装饰器 | @func | f = func(f) |
| 装饰器工厂 | @decorator(x) | f = decorator(x)(f) |
| 对象方法装饰器 | @obj.method | f = obj.method(f) |
| 对象方法工厂 | @obj.method(args) | f = obj.method(args)(f) |
典型应用场景举例
日志记录:
def log(func): @wraps(func) def wrapper(*args, **kwargs): print(f"调用 {func.__name__} 参数: {args}, {kwargs}") return func(*args, **kwargs) return wrapper权限控制:
def require_admin(func): @wraps(func) def wrapper(*args, **kwargs): if not user_is_admin(): raise PermissionError("需要管理员权限") return func(*args, **kwargs) return wrapper性能测试(统计函数运行时间):
import time def timing(func): @wraps(func) def wrapper(*args, **kwargs): start = time.time() result = func(*args, **kwargs) print(f"{func.__name__} 耗时: {time.time() - start:.4f}s") return result return wrapper
Pytorch
stack
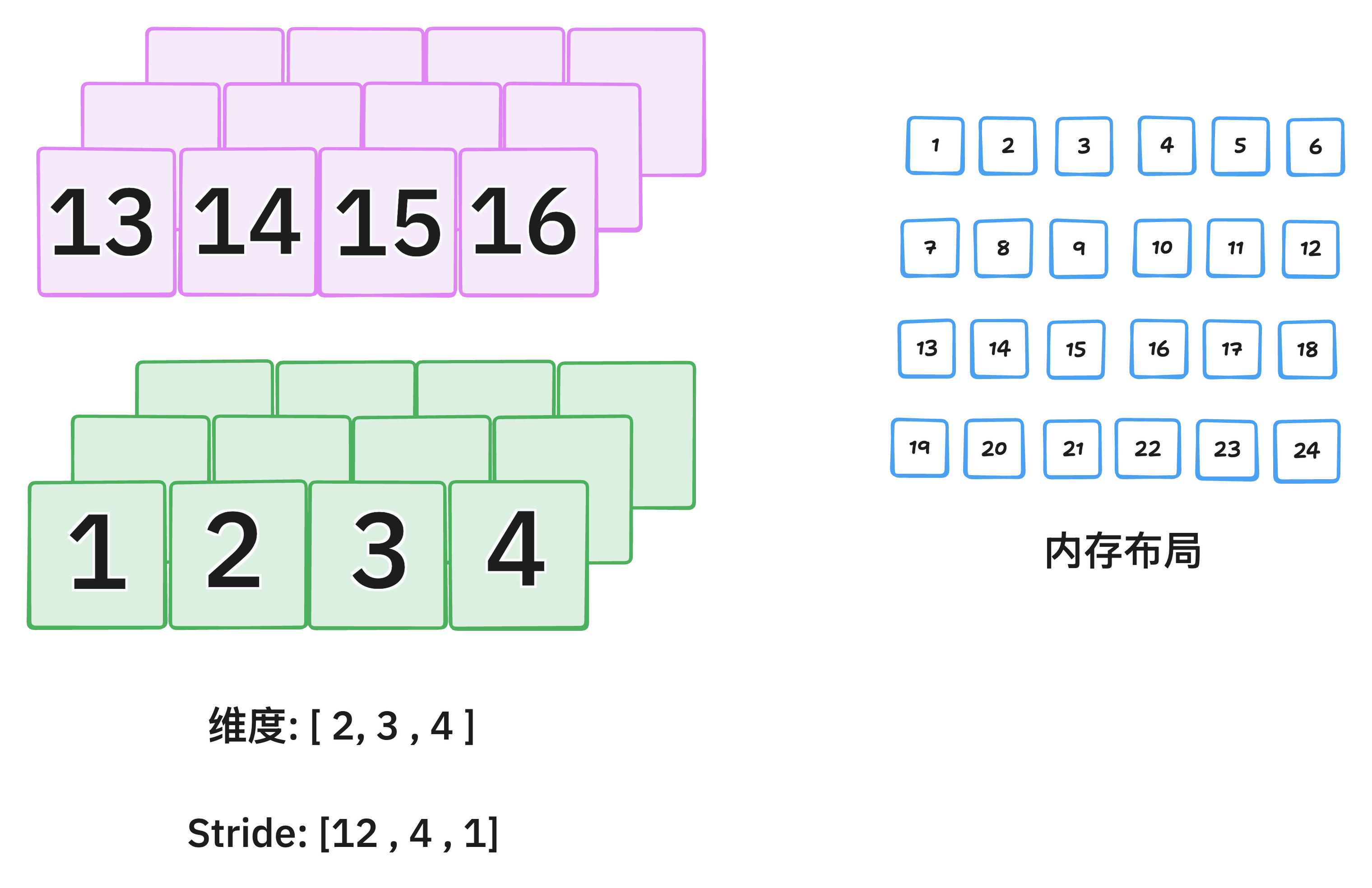
torch.stack() 是 PyTorch 中用于将多个形状相同的张量沿一个新维度拼接的函数。
torch.stack(tensors, dim=0, *, out=None)tensors:一个可迭代对象(如列表、元组),其中包含多个形状相同的 Tensor。
dim:插入新维度的位置(默认是 0)。这个新维度就是拼接的那一维。
out:可选输出张量,用于写入结果。
例子如下:

注意:
所有张量必须具有完全相同的 shape。
如果你想把一个 batch 中的多个样本打包成一个大 tensor,通常会用 torch.stack()。
transpose
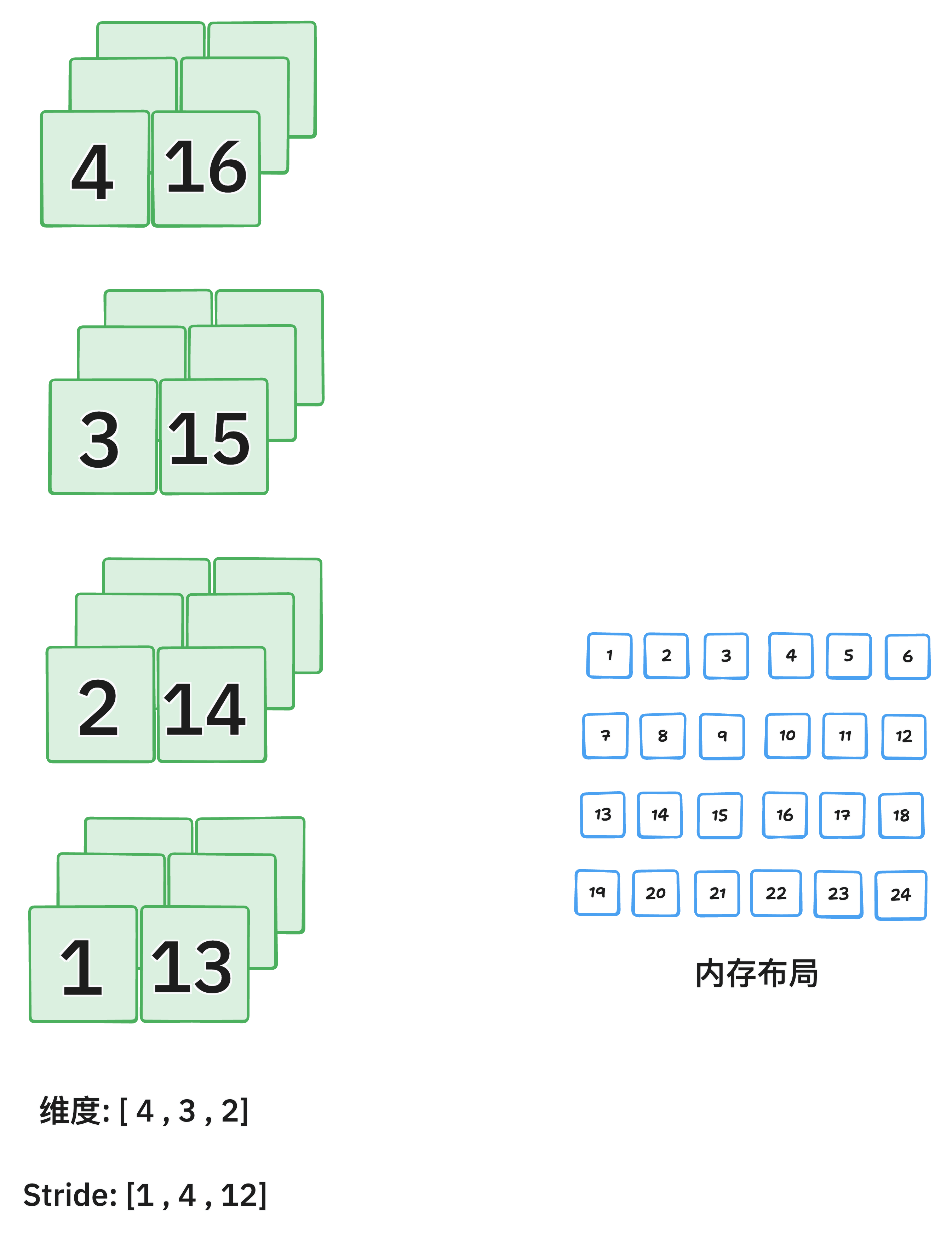
y = x.transpose(dim0, dim1)只交换两个指定维度,常用于 2D 或 3D 张量,如图像转置、RNN 输入调整等。
permute
y = x.permute(dims)可以任意重新排列所有维度,是 transpose 的泛化,支持多维度同时交换。
transpose() 和 permute() 返回的张量虽然是视图(view),但它们的 内存布局(strides)被改变。如果你接下来要对它们执行 .view() 或某些要求内存连续的操作,就必须先调用 .contiguous()。
执行 transpose(0, 2) 后:
view
view: 在不复制数据的前提下,返回具有新形状(shape)的张量视图(view)。
new_tensor = x.view(shape).view() 只适用于连续内存的张量,某些操作(如 permute, transpose)会改变张量的 stride(内存步长),使其变得 非连续。此时必须先 .contiguous() 再 .view():
x = torch.randn(2, 3, 4)
y = x.permute(0, 2, 1) # 改变维度顺序
z = y.contiguous().view(2, -1) # 否则可能报错.view() 不会复制数据,是原张量的一个视图(共享内存)
reshape
reshape: 返回具有新形状的张量。必要时会复制数据,否则返回视图。 相比 .view(),reshape() 不要求原始张量是连续的,这是它最大的优势。
new_tensor = x.reshape(shape)在 PyTorch 中,reshape() 在多数情况下会返回原张量的视图(不复制数据),但当张量的内存布局不连续(例如经过了 permute()、transpose() 等操作),或新形状无法与原内存布局兼容时,reshape() 就会进行数据复制以创建新的张量。此外,如果张量来源于 expand()(广播视图),或者跨设备/特殊操作后的中间结果,也可能触发复制。因此,若希望确保内存效率,建议在 reshape 前使用 .is_contiguous() 检查,必要时用 .contiguous() 转为连续张量。
repeat
tensor.repeat() 是 PyTorch 中用于沿指定维度重复张量内容的操作,它会复制数据,从而扩展张量的形状(不是视图)。
repeated_tensor = x.repeat(repeat_1, repeat_2, ..., repeat_n)参数个数必须和 x 的维度数相同。
每个 repeat_i 表示该维度上复制的次数。
import torch
x = torch.tensor([[1, 2], [3, 4]])
x = x.repeat(2,3)
print(x)
output:
tensor([[1, 2, 1, 2, 1, 2],
[3, 4, 3, 4, 3, 4],
[1, 2, 1, 2, 1, 2],
[3, 4, 3, 4, 3, 4]])expand
tensor.expand() 是 PyTorch 中用于扩展张量尺寸但不复制数据的一种高效方法,它通过广播(broadcasting)机制生成新的视图,节省内存。
expanded_tensor = x.expand(size_1, size_2, ..., size_n)参数个数必须和 x.dim() 相同,或可以通过在前面添加维度来自动广播。
某一维如果是 -1,表示保持原来的大小。
x = torch.tensor([[1], [2], [3]]) # shape: [3, 1]
x.expand(3, 4)
# → 每行复制 4 次,但不占用额外内存
# tensor([[1, 1, 1, 1],
# [2, 2, 2, 2],
# [3, 3, 3, 3]])使用 -1 保留维度:
x = torch.randn(3, 1, 5) # shape: [3, 1, 5]
x.expand(-1, 4, -1) # shape → [3, 4, 5]核心原则:只有原始维度 = 1 的位置,才能通过 expand 变大;其他位置必须 相等。
x = torch.tensor([[1, 2, 3]]) # shape: [1, 3]
y = x.expand(2, 3) # ✅ 第 0 维是 1 → 可以扩展成 2
# ❌ 第 1 维是 3 → 目标仍是 3,虽然没变,但也不能写成 6!
x.expand(2, 6) # ❌ 报错!因为第 1 维是 3,不能变成 6| 特性 | .expand() | .repeat() |
|---|---|---|
| 是否复制数据 | ❌ 否(返回视图,节省内存) | ✅ 是(创建新张量,开销大) |
| 是否支持广播 | ✅ 支持(自动按维度扩展) | ❌ 不支持,必须精确指定每维重复次数 |
| 是否可用于改变维度 | ❌ 否(维度必须兼容) | ✅ 是 |
| 常用于 | 高效广播,如 attention、masking 等 | 实际复制,如构造重复输入 |
@torch.no_grad()
在这个装饰器修饰的函数内,PyTorch 不会跟踪计算图,也不会计算梯度。
这样可以减少内存使用和计算开销,因为不需要保存中间变量用于反向传播。
适用于只需要前向推理且不需要更新模型参数的场景。
register_buffer
# nn.Module 类中提供的方法
register_buffer(name: str, tensor: Optional[torch.Tensor], persistent: bool = True)name (str)
缓冲区的名称(字符串)。
之后可以用 model.name 访问,比如 model.queue。
tensor (torch.Tensor 或 None)
要注册的张量。
这个张量会成为模型的一个成员,但不会被视为可训练参数。
也可以传 None,表示先占位,后面再赋值。
persistent (bool,默认 True,PyTorch 1.8以后支持)
如果为 True,该缓冲区会包含在 state_dict() 中,即会被保存和加载。
如果为 False,缓冲区不会保存到 state_dict(),常用于临时缓存数据。
register_buffer的作用和意义:
它会把一个张量(tensor)作为模型的缓冲区注册,不会被当作模型的可训练参数(不会出现在model.parameters()里,也不会参与梯度计算或优化)。
但是,缓冲区会被自动保存到模型的状态字典(state_dict)中,也会被加载(load)和保存(save)。
常用于保存一些模型的状态信息,但这些信息不需要训练,比如:均值、方差、队列、掩码等。
einsum
einsum 是 爱因斯坦求和约定(Einstein Summation) 的简写,是一个非常强大且直观的张量操作工具。
相比 matmul、bmm、torch.matmul 这类 API,einsum 让你显式指定维度之间怎么相乘/求和/保留。
torch.einsum("维度规则", [tensor1, tensor2, ...])引号中是 对每个 tensor 的维度命名
相同的维度字母表示要做 点积/求和
没有重复的维度字母表示保留该维度
| einsum 表达式 | 等价操作 | 输出形状 | 含义 |
|---|---|---|---|
"nc,nc->n" | (q * k).sum(dim=1) | (N,) | 每个 query 与其正样本的点积 |
"nc,ck->nk" | torch.matmul(q, queue) | (N, K) | 每个 query 与所有负样本的相似度 |
模型
ResNet18
ResNet18是一种深度残差网络,它由18层组成。它的结构包括一个输入层、四个残差块和一个输出层。每个残差块包含两个3x3的卷积层,每个卷积层后面都跟着一个Batch Normalization和ReLU激活函数。此外,每个残差块还包含一条跨层的连接线,将输入直接连接到输出。这种设计使得网络能够更好地处理深层特征,并且可以避免梯度消失问题。ResNet18在图像分类任务中表现出色,可以用于训练大型数据集,如ImageNet。
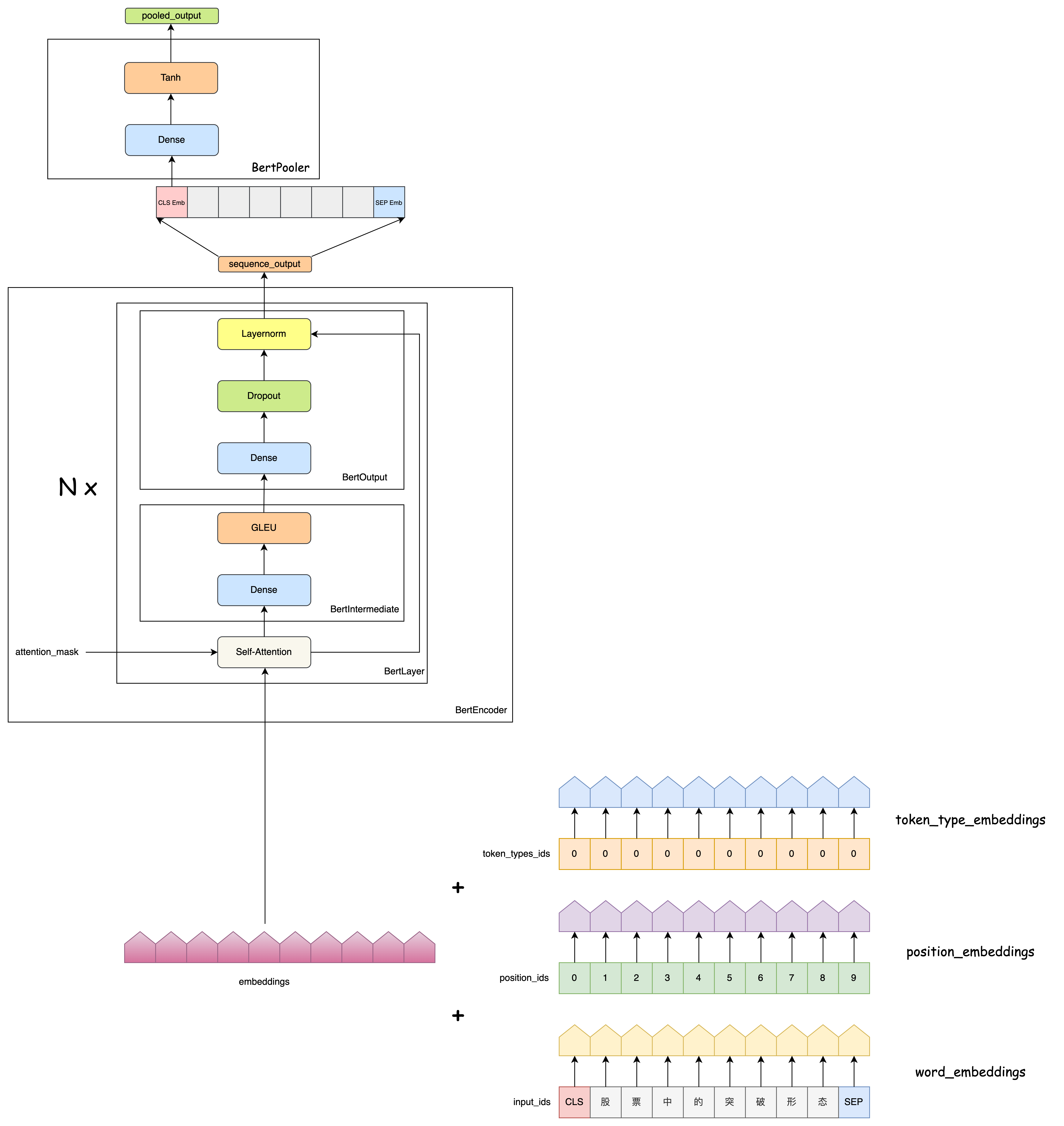
Bert
pooler_output 的输出用于捕获整个句子的全局语义信息:
公式&定理
通用近似定理
以下内容来自: << 神经网络与深度学习 >> 4.3.1 通用近似定理
根据通用近似定理,对于具有线性输出层和至少一个使用“挤压”性质的激活函数的隐藏层组成的前馈神经网络,只要其隐藏层神经元的数量足够,它可以以任意的精度来近似任何一个定义在实数空间中的有界闭集函数.所谓“挤压”性质的函数是指像Sigmoid函数的有界函数,但神经网络的通用近似性质也被证明对于其他类型的激活函数,比如ReLU,也都是适用的.
个人对上述内容的理解
通用近似定理中“隐藏层神经元的数量足够”这一条件,与多项式逼近(如泰勒展开)中 '增加阶数提高精度' 的思想有深刻的相似性,但神经网络的非线性基函数组合比传统多项式逼近更灵活。以下是具体分析:
| 逼近方式 | 多项式逼近(泰勒展开) | 神经网络逼近 |
|---|---|---|
| 基函数 | 单项式基 | 非线性激活后的基 |
| 组合方式 | 线性加权和 | 线性加权和 |
| 逼近原理 | 增加阶数 | 增加神经元数量 |
| 函数空间 | 多项式函数空间 | 自适应生成的非线性函数空间 |
关键共同点:
- 两者都通过增加基函数的数量(多项式阶数/神经元数量)来扩大逼近空间的容量,从而提升对目标函数的拟合精度。
神经网络的独特优势:
自适应基函数
多项式逼近的基函数是固定的(如
示例:拟合分段函数时,ReLU神经元可自动学习“转折点”,而多项式需极高阶数才能近似突变。
维度诅咒的缓解
- 在高维空间(
- 在高维空间(
对非平滑函数的适应性
- 泰勒展开要求函数无限可微,而神经网络(如使用ReLU)可逼近连续但不可微的函数(如
- 泰勒展开要求函数无限可微,而神经网络(如使用ReLU)可逼近连续但不可微的函数(如
案例:逼近区间
多项式逼近: 需高阶泰勒展开
神经网络逼近: 仅需4个Tanh神经元即可高精度拟合,因基函数
理论限制的相似性:
逼近精度与代价的权衡
多项式:高阶项导致数值不稳定(如大数相减损失精度)。
神经网络:神经元过多易过拟合,且训练难度增加(梯度消失/爆炸)。
全局逼近 vs 局部逼近
多项式:调整某一系数会影响全局拟合。
神经网络:可通过局部神经元(如ReLU)实现分段逼近,更适应局部特征。
现代深度学习的延伸: 深层神经网络通过函数复合(Function Composition)能够以指数级减少所需的神经元数量,核心原因在于层次化的函数构造方式比单层网络的线性组合更高效。这与多项式逼近等传统方法有本质区别,具体可以从以下几个方面理解:
1. 函数复合 vs. 线性组合:数学本质对比
单层网络(线性组合):
单隐藏层神经网络的输出形式为:
它通过一组非线性基函数((\sigma))的加权和逼近目标函数,类似于多项式逼近中的基函数组合。要逼近复杂函数,可能需要大量神经元((N) 极大)。
深层网络(函数复合):
每一层
关键区别:
单层网络依赖基函数的数量(宽度)来增加表达能力。
深层网络依赖函数的嵌套深度,通过分层组合简单函数,实现复杂功能。
2. 为什么函数复合更高效?
(1) 分治策略(Divide-and-Conquer)
深层网络将复杂函数分解为多个简单步骤,每一层只需学习局部特征,最后组合成全局解。例如:
目标函数:拟合一个“锯齿波”
单层网络:需要大量神经元构造多个“转折点”。
深层网络:每层学习一个转折点,通过复合实现指数级增长的分段线性区域(如
(2) 指数级表达能力
理论结果:
Telgarsky (2016) 证明:用深度
直观理解:每一层的非线性变换(如ReLU)相当于对输入空间进行一次“折叠”,深度叠加导致表达能力爆炸式增长。
| 网络类型 | 所需神经元/层数 | 表达能力增长方式 |
|---|---|---|
| 单层宽网络 | 线性增长(基函数叠加) | |
| 深层网络 | 指数增长(函数复合) |
(3) 参数复用与模块化
深层网络通过共享参数(如卷积核)和模块化设计(如残差块),进一步减少冗余:
- 示例:CNN中,同一卷积核在不同位置重复使用,避免为每个像素单独建模。
3. 与多项式逼近的对比
多项式逼近通过增加阶数(如泰勒展开)提升精度,但存在两大局限:
全局性:调整某一系数会影响整个函数,难以局部修正。
维度灾难:高维输入时,多项式项数
而神经网络的函数复合:
局部性:每层聚焦不同抽象层次(如边缘→纹理→物体)。
维度友好:通过分层降维(如池化)逐步压缩信息。
4. 实例说明
案例1:逼近“多次折叠”的函数
目标函数:
单层网络:需数百个神经元拟合嵌套正弦波。
深层网络:3层即可,每层对应一个
案例2:图像分类
单层网络:需直接建模像素到类别的复杂映射,参数量极大。
深层CNN:逐层提取边缘→纹理→部件→物体,参数量更少。
5. 理论支持
深度分离定理(Depth Separation Theorem): 存在某些函数,用浅层网络逼近需要指数级神经元,而深层网络只需多项式数量(如 Eldan & Shamir, 2016)。
电路理论类比: 深层网络类似布尔电路中的分层设计(如AND-OR门组合),比单层电路更高效。
6. 深层网络的代价
虽然深度减少了神经元数量,但带来了:
优化难度:梯度消失/爆炸问题。
过拟合风险:需正则化(如Dropout)。
计算开销:并行化要求更高。
总结:
神经网络通过非线性激活函数生成的动态基函数组合,实现了比多项式逼近更高效的函数近似。虽然“增加神经元数量”与“提高多项式阶数”在思想上都体现了用更多自由度提升精度,但神经网络的自适应基函数和分层结构使其:
对高维和非平滑函数更鲁棒
避免了手工设计基函数的局限性
在实践中通过梯度下降自动学习逼近策略
ROI Pooling
在目标检测任务中,比如 Faster R-CNN,我们会从一张图片中生成多个候选区域(ROI),这些区域的大小各不相同。而神经网络的全连接层只能接受固定大小的输入,这就产生了一个问题:
- 如何将不同尺寸的ROI特征,统一变为相同尺寸?
ROI Pooling 的目标就是: 从不同大小的 ROI 区域中提取固定大小的特征(例如 7×7),同时保留最有代表性的空间信息。
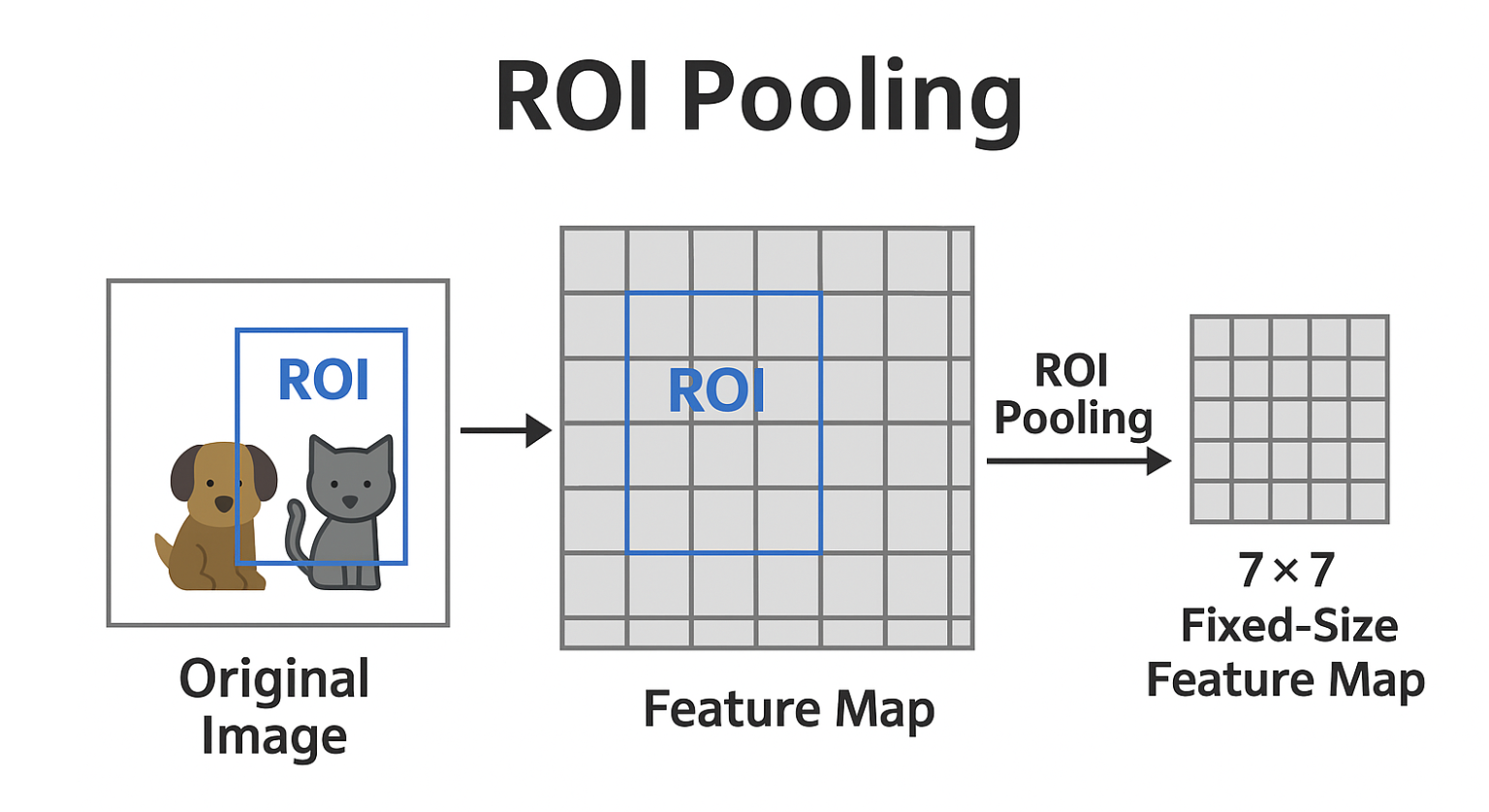
ROI Pooling 的操作流程可以分为三个步骤:
- 映射 ROI 到特征图空间
假设输入图像经过卷积得到一个特征图(例如从 ResNet 输出的特征图),而我们检测到一个 ROI(例如在原图上坐标为
由于特征图的尺寸比原图小(通常是原图的 1/16),我们需要先将 ROI 坐标 映射到特征图上:
其中 stride 是特征图相对于原图的缩放比例。

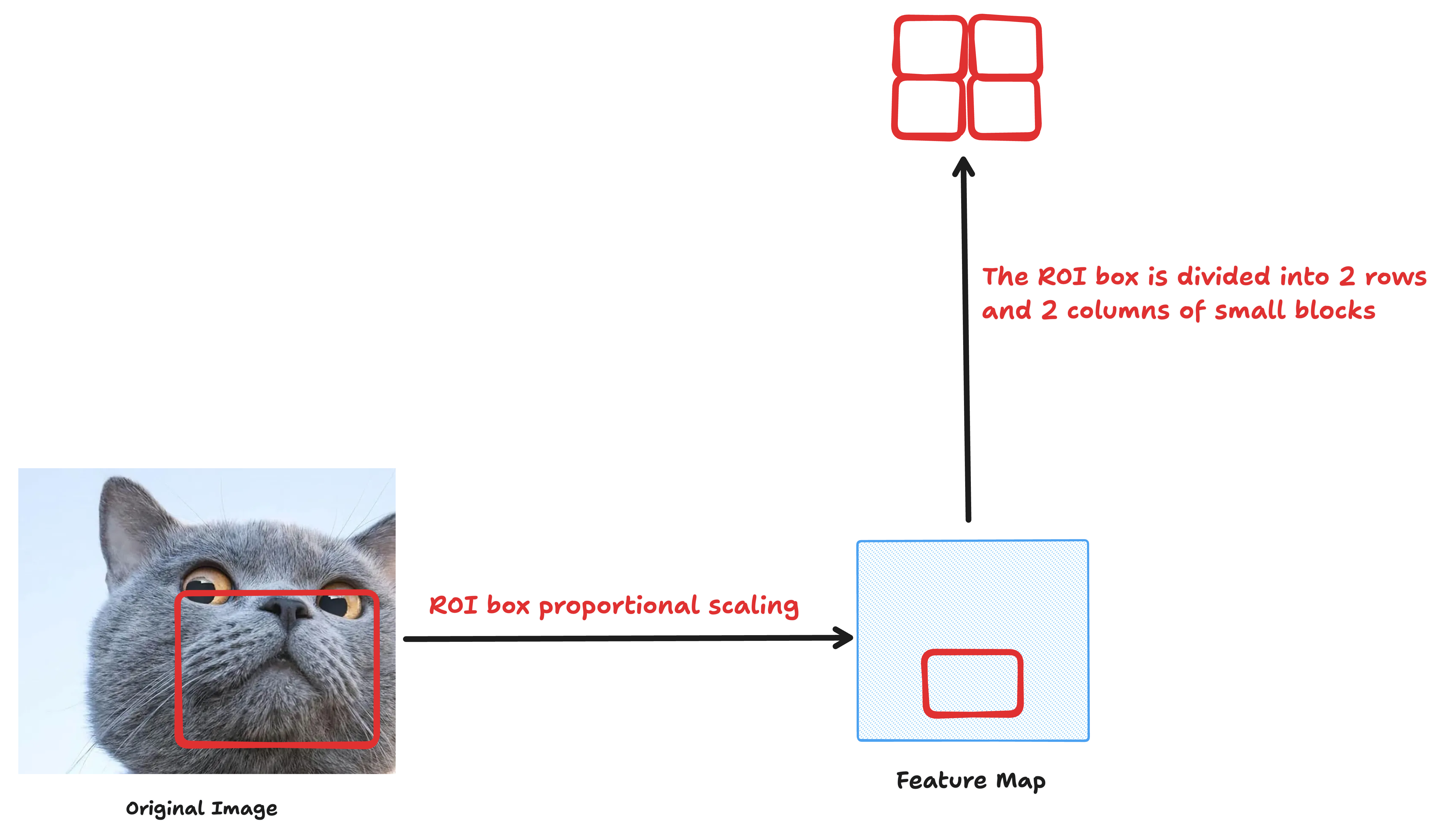
- 将该 ROI 划分成固定数量的网格区域
例如我们希望将每个 ROI 转换成 7×7 的特征图,那么就把该 ROI 分成 7 行 × 7 列的 小块(每一小块大小不同,但数目固定)。
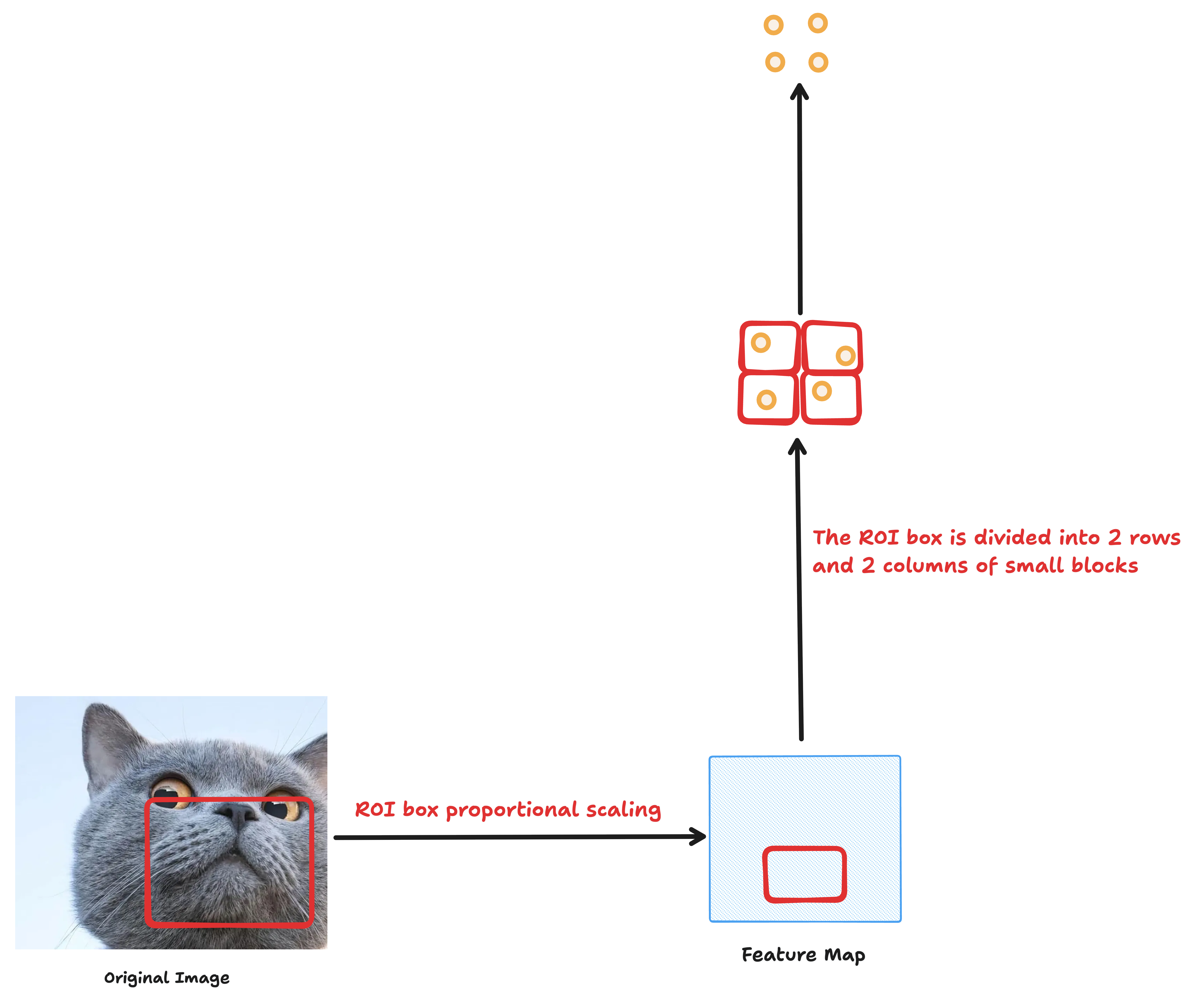
- 每个小块做 max pooling
对每个小块区域做 最大池化(Max Pooling),取出该区域内的最大值,这样就将原本不定尺寸的 ROI 转换成一个固定大小的特征图(例如 7×7)。
假设某个 ROI 映射到特征图上之后是一个大小为 14×14 的区域,我们希望输出一个 7×7 的固定大小特征图。
- 将 14×14 区域划分为 7×7 的网格(每个网格是 2×2 大小)
- 对每个 2×2 的小格子做最大池化 → 输出一个 7×7 特征图
⚠️ ROI Pooling 有一个问题:量化误差。
ROI Pooling 的划分方式中涉及到了取整(floor/ceil),这在某些场景下会导致位置偏差、信息丢失。
为了更精确,Mask R-CNN 提出了更先进的方法:ROI Align,它使用双线性插值来避免量化误差,使得检测/分割性能更好。
ROI Align
ROIAlign 是 Mask R-CNN 中为了解决 RoIPooling 引起的对齐误差问题而提出的关键组件。
RoIPool(Region of Interest Pooling) 是 Faster R-CNN 中的标准组件,用于将任意大小的候选框(RoI)转换为固定大小(例如 7×7)的特征图,以便送入全连接层进行分类和回归。
问题: RoIPool 在处理浮点型的 RoI 坐标时进行了两次量化(quantization)操作:
RoI 边界坐标的量化(例如将 x/16 向下取整);
池化 bin 分割时的量化(每个 bin 的边界坐标再取整)。
这会导致特征图上的空间对齐误差(misalignment),尤其对 像素级别任务如分割 影响显著。
RoIAlign目标:消除量化误差,实现精确的像素级对齐。
实现步骤如下:
- 不进行任何量化
- 保留浮点型的 RoI 坐标值(例如 x/16 而不是 [x/16]),也不对 bin 边界进行离散化。
- 对每个 bin 采样多个点(如 2×2)
将 RoI 分成固定数量的 bin(例如 7×7)。
每个 bin 中选定若干个浮点坐标点(通常为4个采样点,中心或等距分布)。
+----------+
| * * |
| |
| |
| * * |
+----------+每个 * 就是一个采样点,它们分布在 4 个角的中间位置,平均对称。
- 使用双线性插值(Bilinear Interpolation)提取特征值
- 由于坐标是浮点数,不对应实际的 feature map 网格点,因此使用四邻域双线性插值从特征图中获取精确的 feature 值。
你要在 (3.6, 5.2) 点上取值:
- 它离 (3,5) 的距离是 (1 - 0.6) * (1 - 0.2) = 0.4 * 0.8 = 0.32
- 它离 (4,5) 的距离是 0.6 * 0.8 = 0.48
- 它离 (3,6) 的距离是 0.4 * 0.2 = 0.08
- 它离 (4,6) 的距离是 0.6 * 0.2 = 0.12
于是你把这 4 个点的值按这个比例加起来,就得到了 (3.6, 5.2) 的值。
就像你在地图上两个村庄中间估算温度时,不会只看一个村,而是综合周围村子的情况加权得出。每个撒下去的小数点都用周围的4个整数点去“平均估计”(双线性插值);
- 对采样点的值进行聚合
可以采用 max 或 average(论文推荐 average)。
每个 bin 的最终输出为这些采样点值的聚合结果。
图示(见论文 Figure 3):
- 实线为 RoI,虚线为 feature map 网格,黑点为采样点,通过插值获得值后聚合。

RoIAlign 就是:
先把目标区域平均切成小格子(比如 7×7);
在每个小格子里撒几个点(比如 2×2);
每个撒下去的小数点都用周围的4个整数点去“平均估计”(双线性插值);
最后把所有点的值求平均,就得到了这个格子的特征。