
DALL·E 论文解读
论文链接: Zero-Shot Text-to-Image Generation
第三方代码实现: DALL-E
引言
文本生成图像任务传统上是在固定的数据集上,借助复杂的模型架构、辅助损失函数或额外信息(如物体部分标签、分割掩码等)进行训练。虽然这些方法提升了生成效果,但生成图像中仍常见严重问题:
现存问题:
物体扭曲,形状不自然
物体摆放不合逻辑,空间关系混乱
前景与背景融合不自然,视觉体验差
这些问题限制了模型在实际应用中的表现。 从2015年起,研究者尝试用不同生成模型改善文本到图像的转换。最初,Mansimov 等人用变分自编码器 DRAW 模型进行尝试;随后,Reed 等人用生成对抗网络提升了图像质量和泛化能力。此后,研究不断融合新的方法:
多尺度生成器架构
引入注意力机制和辅助损失
利用额外条件信息,如除文本外的其他标签
此外,基于能量模型的方法和优化预训练跨模态模型输入的方式也出现,进一步提升了样本质量。尽管如此,生成的图像依然存在明显的瑕疵。
近期,大规模模型和海量数据的结合,尤其是自回归 Transformer 架构,已在文本、图像和音频领域取得显著成果。相比之下,文本生成图像的研究多基于较小数据集(如 MS-COCO、CUB-200),模型规模和数据量可能是性能瓶颈。本研究训练了一个参数量为
该模型能够灵活生成高质量图像,且通过自然语言实现控制
在 MS-COCO 数据集的零样本测试中表现优异,不依赖任何训练标签
人类评估显示,生成图像在
模型具备一定的图像到图像转换能力,这一复杂任务以前通常需要专门设计的方案才能实现
这表明,大规模统一建模方法具备强大的泛化与多任务能力。
方法
我们的目标是训练一个 Transformer,以自回归的方式将文本和图像 token 作为单一的数据流进行建模。然而,若直接使用像素作为图像 token,对于高分辨率图像将需要大量的内存。似然(Likelihood)目标倾向于优先建模像素之间的短程依赖,因此,大量的模型容量会花在捕捉高频细节上,而非低频结构上——而低频结构才是使得物体在视觉上可被我们辨认的关键。
为了解决这些问题,我们采用了类似的两阶段训练流程:
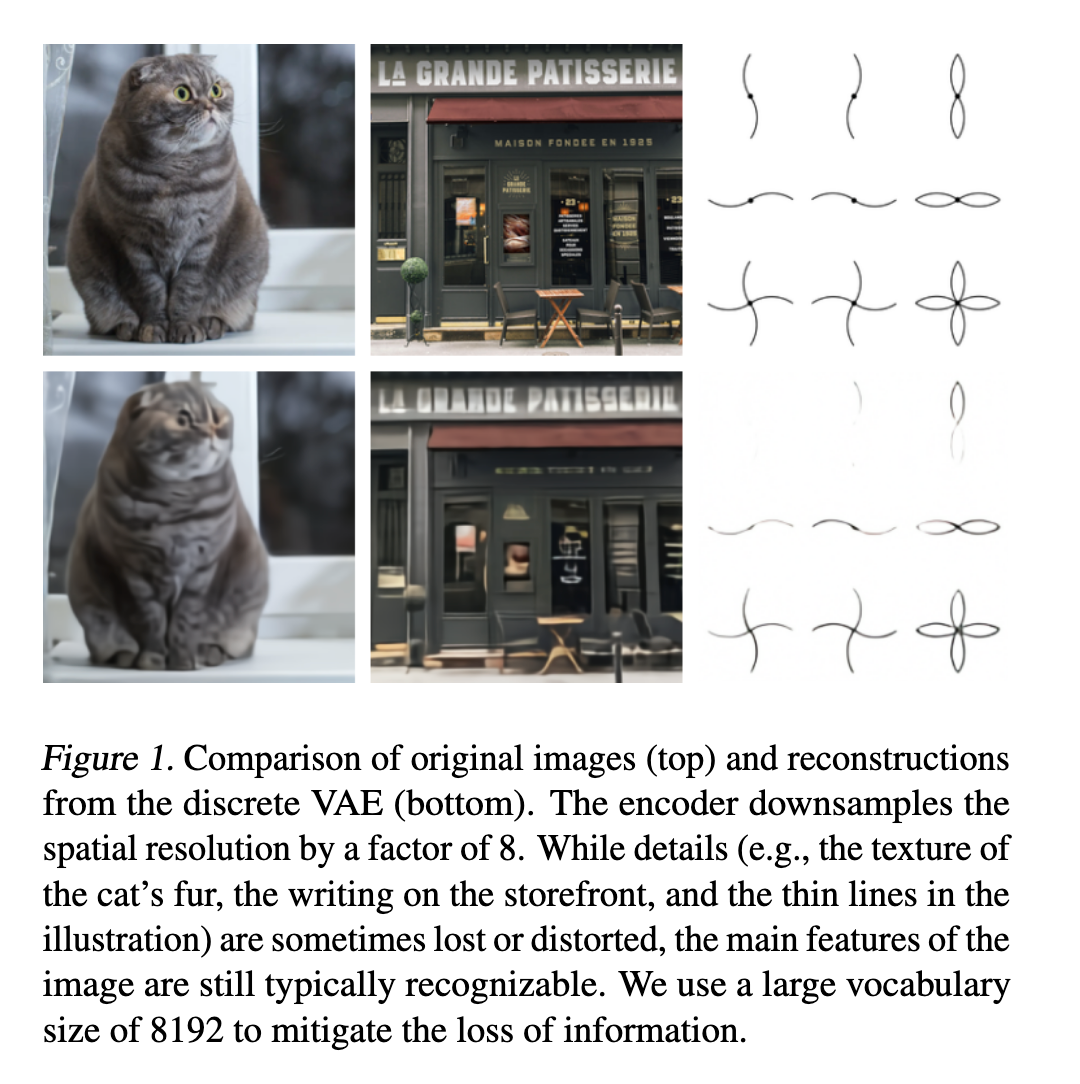
阶段 1:我们训练一个离散变分自编码器(dVAE)¹,将每个 256×256 的 RGB 图像压缩成一个 32×32 的图像 token 网格,其中每个元素可以取 8192 种可能的值。这使得 Transformer 的上下文长度减少了 192 倍,而视觉质量没有显著下降(见图 1)。
阶段 2:我们将最多 256 个 BPE 编码的文本 token 与 32×32 = 1024 个图像 token 拼接起来,训练一个自回归 Transformer 来建模文本和图像 token 的联合分布。
整体流程可以被视作在最大化模型分布在图像
其下界为:
其中:
需要注意的是,该下界仅在
关于上面部分公式的补充解读:
这样一来,整个生成过程可以想成:
先从 Transformer 的联合先验
再用 dVAE 解码器
意思是: 图像和文本的联合概率,可以拆成 “根据文本和图像 token 生成像素图像” × “文本和图像 token 的联合概率”。
这样分开好处是:
互不干扰,分工明确。
ELBO 公式的含义
因为
第一项
第二项
两阶段如何对应这个公式
阶段一(学
阶段二(学
ELBO 公式推导过程
这里:
我们希望得到:
但由于
然后套入 Jensen 不等式 (
注意到:
如果把
然后他们在 KL 前乘了一个经验选择的系数
用变分后验
代入 Jensen 不等式得到下界;
分离出“重构项”和“KL 正则项”;
在 KL 项前加权得到 β-ELBO。
阶段一:学习视觉码本(Visual Codebook)
在第一阶段训练中,我们最大化关于
此时,ELB 的优化变得困难:由于
我们使用 Adam 优化该松弛的 ELB,并采用指数加权的迭代平均(iterate averaging)。附录 A.2 给出了完整的超参数描述,但我们发现以下几点对稳定训练尤其重要:
松弛温度与步长的退火策略:我们将
在编码器末端与解码器开头使用 1×1 卷积:我们发现,在松弛操作附近减小卷积感受野有助于其对真实 ELB 的泛化;
对编码器和解码器残差块的输出激活乘以一个较小的常数,以确保初始化时的稳定训练。
我们还发现,将 KL 权重增加到
阶段二:学习先验
在第二阶段中,我们固定
给定一对文本-图像数据,我们将小写化的标题用 BPE 编码,最多 256 个 token,词汇表大小为 16,384;图像则用 32×32 = 1024 个 token 表示,词汇表大小为 8192。图像 token 由 dVAE 编码器 logits 通过 argmax 采样得到(不添加 Gumbel 噪声)。最后,将文本和图像 token 拼接,并作为单一的数据流进行自回归建模。
该 Transformer 是一个 仅解码器(decoder-only) 架构,其中每个图像 token 在其 64 层自注意力层中的任一层都可以访问所有文本 token。完整架构见附录 B.1。模型中使用了三种不同的自注意力掩码:
文本到文本部分使用标准的因果掩码;
图像到图像部分则使用行、列或卷积注意力掩码。
我们将文本标题的最大长度限制为 256 个 token,但在最后一个文本 token 与“图像起始 token”之间的“填充”位置处理方式并不完全确定。一种方法是在自注意力运算中将这些 token 的 logits 设为
我们将文本与图像 token 的交叉熵损失分别按批次中该类型 token 的总数进行归一化。由于我们主要关注图像建模,将文本的交叉熵损失乘以
数据收集
我们在 Conceptual Captions 数据集上进行了最高至 12 亿参数模型的初步实验,该数据集包含 330 万对文本-图像对,是 MS-COCO 的扩展版本。
为了扩展到 120 亿参数规模,我们从互联网收集了 2.5 亿对文本-图像数据,构建了一个与 JFT-300M 规模相当的数据集。该数据集不包含 MS-COCO,但包含 Conceptual Captions 以及经过筛选的 YFCC100M 子集。由于 MS-COCO 是从 YFCC100M 创建的,因此我们的训练数据中包含了一部分 MS-COCO 验证集图像(但不包括其标题)。在第 3 节的定量结果中,我们对此进行了控制,发现这对结果没有显著影响。关于数据收集过程的更多细节见附录 C。
采样生成
我们用一个预训练的对比模型(如: CLIP)来对从 Transformer 生成的图像进行重新排序。给定一条文字描述和一张候选图像,这个对比模型会根据图像和文字的匹配程度给出一个评分。

图 6 展示了当我们从更多的样本数量 N 中选出排名前 k 的图像时,效果是如何变化的。这个过程可以理解为一种由语言引导的搜索,也类似于 Xu 等人(2018)提出的辅助文本-图像匹配的训练方法。
除非特别说明,文中所有用于展示效果和评测的样本,都是在没有调整温度(即温度 t=1,图 2 除外)的情况下生成的,并且都采用了用 N=512 个样本进行重排序的策略。
混合精度训练和分布式优化部分略过。